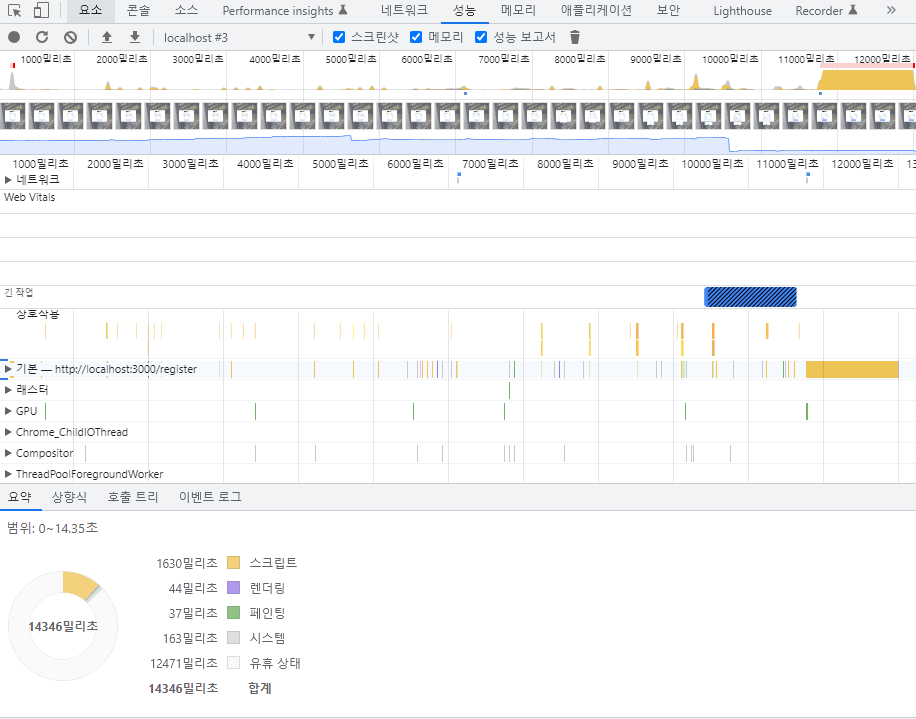
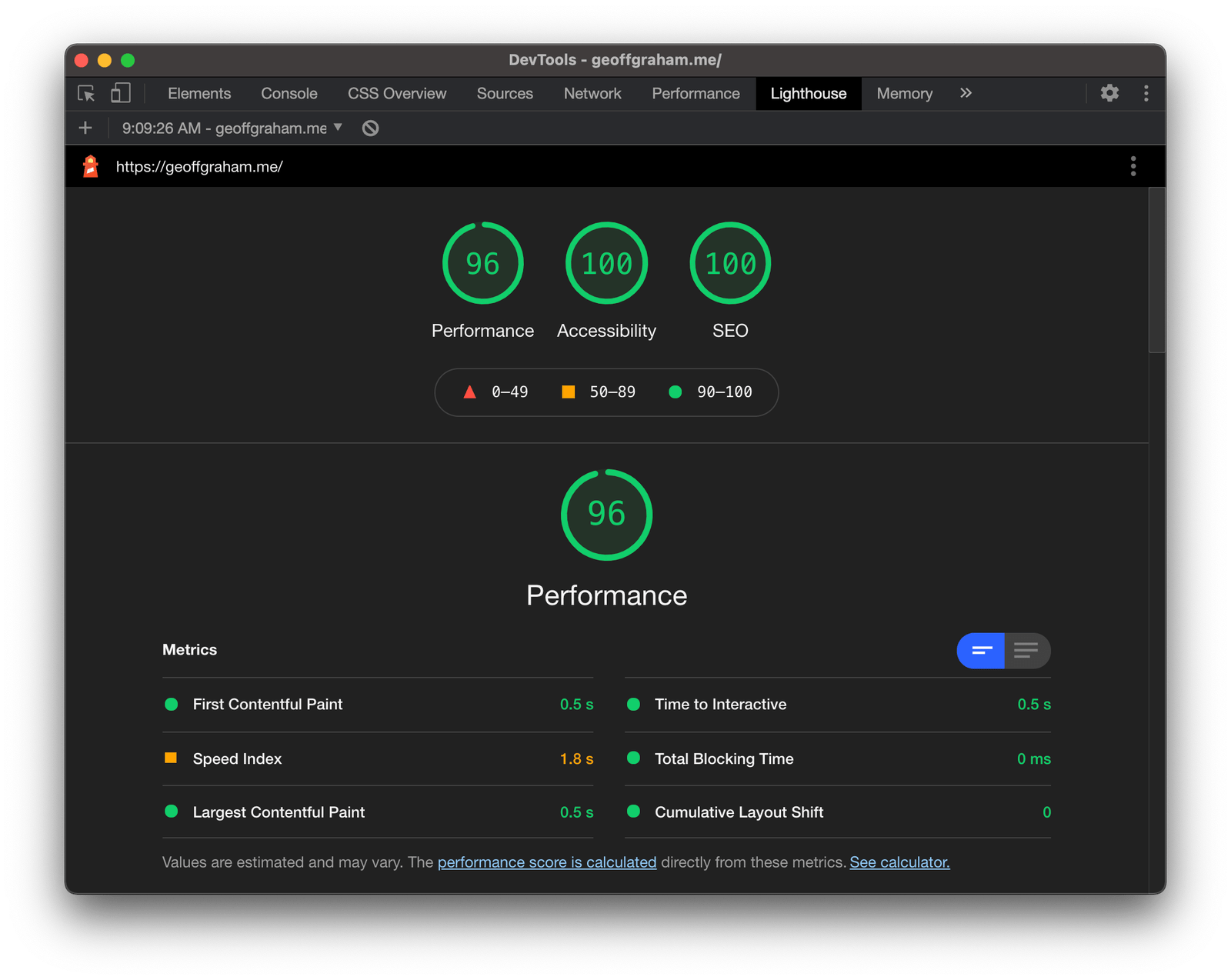
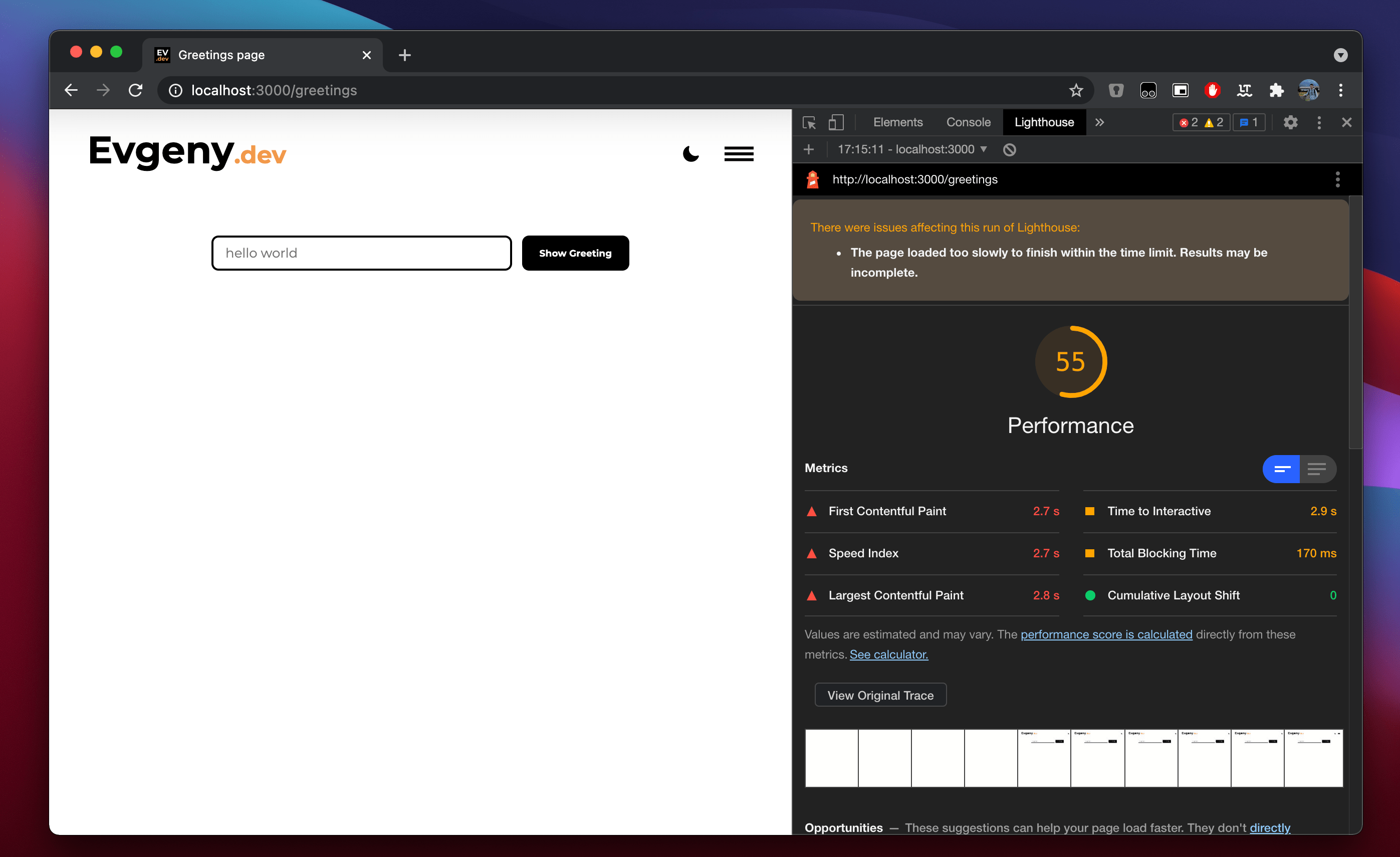
비교결과, 라이트하우스 결과에서 보듯이 useCallback을 사용하지 않더라도 전반적인 성능에 큰 영향이 없었다.
오히려, 리팩토링 과정에서 추가적으로 내부에서 useState로 관리하는 상태값을 줄인 덕분에 오히려 랜더링 횟수가 감소하였고 속도도 빨라졌다.
이를 통해, useCallback의 유무가 현재 코드 상에서는 전체적인 성능에 영향을 주지 않았고 리팩토링 과정에서 추가적으로 진행한 상태값을 줄이는 리팩토링이 성능향상에 유의미한 결과를 주었음을 확인할 수 있었다.
useCallback의 사용 유무와 상관없다면, 코드복잡성을 줄이기 위해 useCallback을 사용하지 않는 것이 좋을 것이다.
앞으로 남은 과제
앞으로는 다른 페이지(컴포넌트)들에 대해서도 성능분석을 진행한 후에, 분석 결과를 바탕으로 React Memoization(useMemo, useCallback, React.memo 등) 기능이 필요한 지에 대한 근거를 먼저 검토하고 필요한 경우에 적재적소에 활용하여 성능을 향상시킬 수 있도록 하고자 한다.
부탁드리는 사항
혹시 잘못된 내용이나, 문제의 소지가 되는 내용이 있다면 언제든 알려주시면 큰 도움이 될 것 같습니다! 또한, 미처 고려하지 못한 Refactoring 사항에 대해서도 피드백 주시면 언제든 환영입니다!
정현이는 자신이 원하는 제품과 수량이 할인하는 날짜와 10일 연속으로 일치한 경우 회원가입 하려고 함
정현이가 가입 가능한 날짜의 총 일수 return
없으면 return 0
입력
1 ≤ want(원하는 제품 문자열 배열), number(원하는 수량 배열) ≤ 10
10 ≤ discount 배열 길이 ≤ 10^5
1 ≤ number의 원소 ≤ 10
number의 원소 합 = 10
출력
return int
불가능하면, return 0
어떻게 풀까?
discount 범위를 생각할 때, O(NlogN) 정도까지 가능
회원가입 일수가 10일 → 슬라이딩 윈도우?
⇒ 회원가입 일수가 10일일 뿐, 1일 안에도 정현이의 want가 모두 채워질 수 있음
⇒ 투포인터로 적용해서 discount for문 한 바퀴(10^5) 돌리면서 조정해주고 그 안에서 want 길이(10)만큼 돌면서 모두 충족되었는지 검사해도 시간복잡도 충분할듯
내 코드
def check_satisfied(want_num):
for want in want_num.keys():
if want_num[want] > 0:
return False
return True
def solution(want, number, discount):
# 데이터 전처리(want, number-> dict)
want_num = dict()
for i in range(len(want)):
want_num[want[i]] = number[i]
# answer 초기화
answer = 0
# discount 돌면서 투포인터 적용
start = 0
end = 0
# 초기화 처리
if discount[start] in want and want_num[discount[start]] > 0:
want_num[discount[start]] -= 1
while end < len(discount):
days = end - start + 1
# 10일 초과 -> start += 1
if days > 10:
if discount[start] in want:
want_num[discount[start]] += 1
start += 1
# 10일 전까지 -> 검사
elif check_satisfied(want_num):
answer += 1
if discount[start] in want:
want_num[discount[start]] += 1
start += 1
# 그 외의 경우
else:
end += 1
if end == len(discount): break
if discount[end] in want:
want_num[discount[end]] -= 1
return answer
일단, 입력 값의 범위를 봤을 때, O(n^2)는 불가능하고 O(nlogn) 정도까지는 가능
제일 먼저 예외처리를 할 수 있는 건, 두 큐의 합이 짝수가 아닐 때! 큐의 합을 모두 더해서 짝수가 아니면 바로 return -1을 해주자!
가장 간단하게 푸는 방법? while 문 돌리면서 각 큐의 합을 비교하고 큰 큐에서 값을 빼서 작은 큐에 넣어주는 것 반복 어차피 FIFO 방식이기 때문에, 결국 돌고 돌면서 크고 작음이 조율될 것! 이때 문제는, 이게 얼마나 돌아야 return -1 판별이 가능한지임 사실 두 q 길이의 합 만큼 돌리면 원상복귀이기 때문에 더 이상 돌 필요가 없음! => 두 q 길이의 합은 2*3*10^5 로 충분히 가능!
이 때, 주의할 점은 deque로 만들어주고 해야한다는 점! 배열에서 바로 pop(0)을 해주면, O(N)이 걸리기 때문(배열에서 앞에걸 빼면 뒤에 원소들도 다 자리이동을 시키기 때문에)에 시간초과가 남 ⇒ deque popleft() 이용 : O(1)
내 코드
다르게 푸는 방법?
투포인터 활용하기!
def solution(queue1, queue2):
target = (sum(queue1) + sum(queue2)) // 2
cur = sum(queue1)
queue3 = queue1 + queue2 + queue1
s = 0
e = len(queue1) - 1
answer = 0
while True:
if cur == target:
return answer
if cur < target:
e += 1
if e >= len(queue3):
return -1
cur += queue3[e]
else:
cur -= queue3[s]
s += 1
answer += 1
GUI(Graphical User Interface), 웹 애플리케이션 또는 소프트웨어의 기능 및 유용성을 테스트하는 테스트 기술 (최종 사용자에게 표시되는 메뉴, 양식, 버튼 및 기타 애플리케이션 요소의 유효성 검사가 포함)
프런트 엔드 테스트의 목표는 전반적인 기능을 테스트하여 웹 애플리케이션 또는 소프트웨어의 프레젠테이션 계층이 연속적인 업데이트로 결함이 없는지 확인하는 것
위의 프런트엔드 테스트 외에도 다음을 위해 수행됨
CSS 회귀 테스트: 프런트엔드 레이아웃을 깨는 사소한 CSS 변경
프런트엔드를 작동하지 않게 만드는 JS 파일 변경
성능 확인
Front-End Test는 왜 할까?
안전한 프로덕션 배포(예: 해당 앱이 단순히 작동)를 보장하고 싶고, 사용자 상호 작용의 전체 주기 동안 애플리케이션이 안정적으로 유지되는지 확인하고 싶을 수도 있음
1. 클라이언트 측 성능 문제 감지
이것이 중요하지만 프런트 엔드 테스트를 통해 사용자 관점에서 서비스 테스트 가능
프런트 엔드 테스트를 통해 클라이언트 측의 문제를 정확히 확인하고 애플리케이션의 중요한 워크플로우의 안정성을 확인할 수 있음
사용성, 탐색 및 페이지 로드 속도와 같은 요소는 사용자와 검색엔진의 순위 알고리즘 모두에 중요
성능이 낮은 UI는 특히 중요한 워크플로가 손상된 경우 리드 또는 수익 창출 채널에 피해를 줄 수 있음
애플리케이션 프런트 엔드의 미묘한 오류가 돌이킬 수 없는 손상을 일으킬 수 있다는 것임
최종 사용자보다 먼저 시스템의 결함을 발견해야 하며 여기에서 프런트 엔드 테스트가 시작됨
즉, 무한 로딩 시간 또는 사용자가 종료할 수 없는 오류 상태와 같은 영역을 포함할 수 있는 애플리케이션의 취약하거나 중요한 부분에서 엣지 케이스를 보호해야 함
이러한 사항을 확인하기 위해 수행하는 테스트는 특정 요구 사항에 따라 수동 또는 자동일 수 있음
2. 다양한 브라우저 및 시스템에서 애플리케이션 동작 검증
프런트 엔드 테스트는 다양한 운영 체제, 브라우저 및 장치에서 웹 애플리케이션의 동작을 확인할 때 중요한 역할을 함
프런트 엔드를 테스트할 수 있는 수많은 브라우저와 OS 조합이 있음
다양한 시스템 아키텍처에서 애플리케이션의 기능 및 응답성을 검증하는 데 도움이 됨
이는 브라우저 기술의 수정과 결합된 클라이언트 측 개발의 발전으로 인해 호환성 문제가 발생할 수 있기 때문에 특히 중요함
따라서 프런트 엔드 테스트는 웹 사이트 또는 애플리케이션이 다른 장치 및 브라우저 엔진에서 동일하게 렌더링되는지 확인하는 데 필요
3. 사용자 상호 작용 및 경험의 품질 향상
프런트 엔드 테스트는 개발 팀이 이러한 성능 벤치마크를 최적화하여 사용자에게 더 나은 경험을 제공하는 데 도움이 됨
보다 구체적으로, 애플리케이션 로드 시간을 줄이고 애플리케이션의 콘텐츠가 올바르게 표시되도록 하며 다양한 장치 및 브라우저에서 인터페이스에 통합된 모양을 제공할 수 있음
이러한 클라이언트측 요소를 테스트하고 개선하면 애플리케이션의 품질이 기하급수적으로 향상될 수 있고 사용자는 다양한 환경에서 더 좋고 일관된 경험을 즐길 수 있을 것
4. 타사 서비스의 원활한 통합 보장
거의 모든 최신 애플리케이션은 어느 시점에서 타사 서비스와의 통합이 필요할 수 있음
특히 SaaS(Software as a Service) 플랫폼이 점차 인기를 얻고 있는 지금에는 그 가능성이 더 높음
애플리케이션에 다른 서비스를 통합할 때 성능이 좋지 않은 스크립트로 인해 손상될 수 있음
이는 사용자가 애플리케이션과 상호 작용할 때 사용자 경험에 상당한 피해를 줄 수 있기 때문에, 타사 서비스를 웹 애플리케이션에 통합하려는 사람에게는 프런트 엔드 테스트가 필수적임
5. 여러 개발자가 참여하는 프로젝트에서 코드 신뢰성 보장
최신 애플리케이션의 복잡성이 증가함에 따라 대규모 프로젝트를 단독으로 제공할 수 있는 경우는 거의 없음
누구도 다른 프로그래머가 작성한 모든 코드 조각에 대해 모든 것을 알 수는 없으며, 이것이 코드가 일관성이 없고 프런트엔드 기능이 손상되지 않았는지 다시 확인하는 프런트엔드 테스트가 중요한 이유임
6. 테스트 문서의 유효성
잘 관리된 테스트를 유지해야 하는 또 다른 좋은 이유는 테스트가 실제 문서로 제공되기 때문
테스트를 작성하려면 특정 테스트(및 관련된 애플리케이션의 구성 요소)가 수행하는 작업에 대한 적절한 설명이 필요합니다.
적절한 테스트를 실행하려면 구성 요소의 API를 사용하여 모의를 추가해야 하고, 나중에 다른 개발자나 팀이 나중에 어떻게 사용할 수 있는지에 대한 지침이 될 수 있음
7. 코드 가독성 향상 및 결합도를 낮출 수 있음
test suite를 작성하면 애플리케이션 코드의 가독성을 높이고 결합도를 낮출 수 있음
개발자가 응용 프로그램의 작은 청크를 테스트하고 싶지만 테스트와 반드시 관련되지 않은 몇 가지 종속 구성 요소 및 모의를 스핀업해야 하는 경우 이는 코드의 일부를 리모델링해야 한다는 신호일 수 있음 (⇒ 코드 부분 간의 상호 의존성이 너무 빡빡하다는 신호)
더 깨끗한 코드는 더 테스트하기 쉽고 테스트 가능한 코드는 더 깨끗함 ⇒ 이는 프런트엔드 개발자 와 궁극적으로 애플리케이션의 최종 사용자에게 윈-윈 시나리오임
결론
프런트엔드 테스트는 프런트엔드 기능, GUI 및 사용성을 테스트하거나 확인하는 것
프런트엔드 테스트의 주요 목표는 모든 사용자가 버그로부터 잘 보호되는지 확인하는 것
프런트엔드 테스트 계획을 작성하면 프로젝트에서 다루어야 하는 장치, 브라우저 및 시스템을 파악하는 데 도움이 됨
또한 프로젝트 범위에 대한 완전한 명확성을 얻는 데도 도움이 됨
Front End Testing 계획
테스트 시, 집중해야 할 몇 가지 측면
애플리케이션의 프런트엔드를 테스트할 때 집중해야 할 몇 가지 측면이 있음
브라우저 간 및 플랫폼 간 기능
다양한 브라우저, 플랫폼 및 장치에서 앱의 기능과 응답성을 모두 확인
접근성
시각 또는 청각 장애가 있는 사람을 포함하여 모든 사람이 애플리케이션에 액세스할 수 있는지 확인
end-to-end 확인
사용자가 취할 가능성이 있는 실제 작업을 모방하여 애플리케이션의 end-to-end 워크플로(백엔드에서 프런트엔드로)를 확인하고 확인하는 데 필요
이미지 분석 테스트
요즘 대부분의 웹사이트와 앱에는 표준 디스플레이 이미지에서 로고, 인포그래픽 및 배너에 이르기까지 많은 이미지가 있음. 애플리케이션의 크기가 크게 증가하므로 테스트를 실행하여 앱이 더 빠르게 실행되도록 이미지를 최적화할 수 있는 위치를 확인해야 함
CSS(Cascading Style Sheets) 테스트
두 가지 주요 CSS 요소인 구문 및 디스플레이의 성능을 보장하기 위해 테스트를 실행해야 함.
계획의 4단계
1단계) 테스트 계획 관리를 위한 도구 찾기
2단계) 프런트 엔드 테스트를 위한 예산 결정
3단계) 전체 프로세스의 타임라인 설정
4단계) 프로젝트의 전체 범위를 결정(범위에는 다음 항목 포함)
사용자가 사용하는 OS 및 브라우저 사용자의 ISP (*ISP : 인터넷 서비스 제공자)
사용자들이 많이 사용하는 기기
사용자의 숙련도
사용자의 인터넷 수정 속도
FIRST 원칙
프런트엔드 테스트는 중요하지만 테스트를 실행할 때 모범 사례를 보장하기 위해 특정 원칙을 고수하는 것도 중요
그렇지 않으면 테스트 결과를 완전히 신뢰하지 못할 수 있음
프런트엔드 테스트의 모범 사례를 고수하려면 따라야 할 프레임워크가 필요한데, FIRST 원칙을 사용가능함
FIRST 원칙은 다음을 의미합니다.
Fast : 빠른
Independent : 독립적인
Repeatable : 반복 가능한
Self-validating : 자체 검증 가능한
Thorough & Timely : 철저하고 적시에
테스트는 신속하게(수명 주기의 필요한 시점에서) 실행되어야 하고, 테스트되지 않은 구성 요소와 격리되어야 하며, 미래에 쉽게 반복할 수 있어야 하고, 테스트 통과 여부를 스스로 검증할 수 있어야 하며 필요한 모든 변수를 다룰 수 있어야 함
프런트엔드 요소의 우선 순위 지정
프런트엔드 테스트는 수백 또는 수천 개의 UI 및 기능 요소를 분석하고 확인하는 것을 의미
UI 요소에는 서식, CSS, 텍스트, 그래픽 등이 포함되며 기능 요소에는 양식, 링크, 버튼 등이 포함됨
효과적인 테스트 프로세스를 보장하려면 먼저 테스트할 항목의 우선 순위를 지정해야 함
페이지 로드 속도, 기본 텍스트, 이미지 및 필수 기능(예: 장바구니에 항목 추가, 결제 도구)을 먼저 테스트하고 그래픽 및 팝업으로 이동하기 전에 테스트하는 것이 합리적일 것
이러한 각 요소가 표시되고 반응하는지 확인한 다음 그래픽 및 레이아웃 확인으로 이동
실제 브라우저 및 장치 사용
실제 브라우저와 장치를 사용하는 것은 오류 없이 실제 환경을 최대한 반영하는 신뢰할 수 있는 프런트엔드 테스트를 수행하는 데 필수적임
에뮬레이터 및 시뮬레이터 사용을 피하고 실제 브라우저 및 장치를 사용하여 시간과 리소스를 절약하면 소프트웨어 테스트 결과를 훨씬 더 신뢰할 수 있음
테스트를 위한 팁
예산, 자원 및 시간을 현명하게 준비
테스트가 더 빨리 실행되도록 헤드리스 브라우저를 사용
더 빠른 실행을 위해 테스트에서 DOM 렌더링의 양을 줄이기
테스트 사례를 격리하여 버그의 근본 원인을 신속하게 파악하여 더 빠른 결함 수정 주기
더 빠른 회귀 주기를 위해 테스트 스크립트를 재사용이 가능하게 만들기
테스트 스크립트에 일관된 명명 규칙을 사용
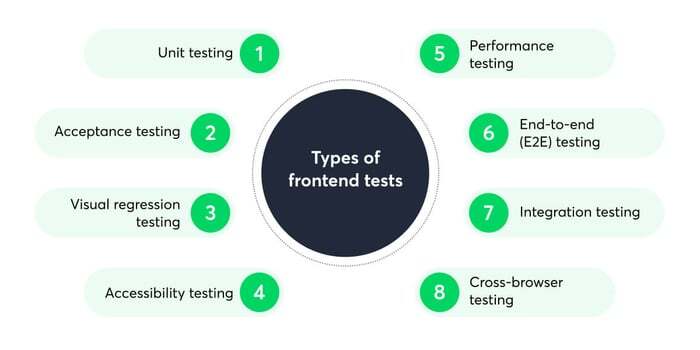
프런트엔드 테스트 유형
프런트엔드에 대해 테스트할 여러 요소가 있으므로 실행을 고려할 수 있는 몇 가지 다른 유형의 테스트가 있고 이들 각각은 프런트엔드의 서로 다른 구성 요소에 초점을 맞추고 있음
단위 테스트
단위 테스트는 프런트엔드 테스트의 기본 빌딩 블록임
개별 구성 요소와 기능을 분석하여 예상대로 작동하는지 확인
이는 모든 프런트엔드 애플리케이션에 매우 중요하며 프로덕션 환경에서 예상되는 작동 방식에 대해 구성 요소 및 기능을 테스트하여 고객을 위한 안정적인 코드베이스와 신뢰할 수 있는 앱으로 이어짐
에지 케이스 및 테스트 API와 같은 항목에 단위 테스트를 사용할 수도 있음
Acceptance 테스트
수락 테스트는 사용자 입력, 사용자 흐름 및 프런트엔드의 지정된 작업이 코딩되고 제대로 작동하는지 확인하기 위해 수행됨
애플리케이션의 최종 모델이 최종 사용자가 기대하는 대로 작동하는지 확인하기 위해 이를 수행
Visual Regression(시각적 회귀) 테스트
시각적 회귀 테스트는 고유한 프런트엔드 테스트임
다른 유형의 테스트는 코드에 중점을 두므로 백엔드 스택에 대해서도 실행할 수 있음
차례로 시각적 회귀 테스트는 응용 프로그램의 실제/기존 인터페이스를 해당 '예상' 버전과 비교하여 차이를 식별함
이는 헤드리스, 서버 실행 브라우저의 스크린샷을 비교하여 이루어지며, 머신을 사용하여 스크린샷 간의 이미지 비교를 수행하고 차이점을 식별하고 강조 표시함
접근성 테스트
접근성 테스트는 시각 장애가 있거나 기타 추가 요구 사항이 있는 개인을 포함하여 모든 잠재적 사용자가 응용 프로그램이나 웹 사이트를 쉽게 사용할 수 있는지 확인함
때때로 사용성 테스트의 하위 범주로 간주되며 특정하고 변경 불가능한 조건으로 인해 앱의 기능에 액세스하는 데 방해가 되지 않고 다른 사람처럼 쉽게 인터페이스를 탐색할 수 있는지 확인함
성능 시험
성능 테스트는 속도, 안정성, 확장성, 상호 운용성 및 응답성을 포함한 특정 매개변수 내에서 애플리케이션의 성능을 분석함
사용자 로드가 증가할 때 제품이 원하는 품질을 유지하고 사용자 요청 및 작업에 빠르고 신속하게 응답하는지 확인하는 데 도움이 되므로 프런트엔드 테스트에 중요함
종단간(E2E) 테스트
종단 간 테스트는 응용 프로그램의 흐름이 처음부터 끝까지 예상대로 작동하는지 확인하고 확인하는 데 사용됨
주로 실제 시나리오 내에서 실제 사용자의 작업을 모방하여 응용 프로그램의 인터페이스와 API 간의 원활한 통신이 원활하게 실행되도록 함
이렇게 하면 함께 결합된 여러 시스템 요소의 결합된 동작에 대한 통찰력을 얻을 수 있음
통합 테스트
대부분의 최신 애플리케이션은 다양한 모듈로 구축됨
이러한 모듈이 제대로 통합되지 않고 함께 잘 작동하지 않으면 최종 사용자 경험을 망칠 수 있음
모든 것이 효과적으로 함께 작동하는지 확인하려면 통합 테스트를 실행해야 함
브라우저 간 테스트
브라우저 간 테스트는 응용 프로그램이 다른 웹 브라우저에서 예상대로 작동하는지 확인하기 위해 수행됨
이 프로세스에는 서로 다른 브라우저에서 동일한 테스트 케이스 세트를 실행하여 애플리케이션이 각 브라우저에서 호환되는지 확인하는 작업이 포함됨
이러한 테스트는 매번 동일하므로 이 프로세스를 자동화할 수 있음
Front-End 테스트 도구
Jest
Jest는 단순성에 중점을 둔 가장 인기 있는 JavaScript 테스트 프레임워크 중 하나
테스트에 고유한 전역 상태가 있는지 확인함으로써 Jest는 테스트를 병렬로 안정적으로 실행할 수 있음
작업을 빠르게 하기 위해 Jest는 이전에 실패한 테스트를 먼저 실행하고 테스트 파일이 걸리는 시간에 따라 실행을 재구성함
또한 강력한 코드 커버리지와 손쉬운 조롱 도구를 제공
Selenium WebDriver
Selenium WebDriver는 개발자가 브라우저 간 테스트를 실행할 수 있는 웹 프레임워크임
호환성을 확인하기 위해 웹 기반 애플리케이션 테스트를 자동화하는 데 사용
이 도구를 사용하면 프로그래밍 언어를 선택하여 브라우저 간 테스트를 위한 테스트 스크립트를 만들 수 있음
크로스 브라우저 테스트, 웹 테스트 및 웹 사이트의 올바른 기능이 확인되었는지 확인하는 데 효과적으로 사용할 수 있음
자동화된 스크립트는 다양한 플랫폼과 여러 브라우저에서 웹 애플리케이션용으로 사용자가 작성할 수 있음
많은 플러그인과 녹음 및 재생 솔루션을 제공하며, 브라우저와 직접 상호 작용하여 효율적이고 빠름
Cypress
Cypress는 웹 테스트 자동화를 위한 종단 간 테스트 프레임워크
단위 테스트, 통합 테스트, 종단 간 테스트와 같은 다양한 테스트를 효율적으로 작성할 수 있음
이를 통해 프런트엔드 개발자는 JavaScript로 자동화된 웹 테스트를 작성할 수 있음
Cypress Syntax의 사용편의성이 좋음
Cypress는 브라우저 내부에서 직접 작동할 수 있습니다. 브라우저의 동작을 수정할 수 있으며 인터페이스를 통해 오류를 쉽게 찾을 수 있음
WebDriverIO
WebdriverIO는 최신 웹 및 모바일 애플리케이션을 자동화하기 위해 구축된 진보적인 자동화 프레임워크임
앱과의 상호 작용을 단순화하고 확장 가능하고 강력하며 안정적인 test suite를 만드는 데 도움이 되는 플러그인 세트를 제공
NodeJS를 기반으로 구축되었으며 JavaScript 언어로 작성되었음.
간결한 스크립트 작성 기능이 제공되며 구조가 간단함
또한 타사 테스트 솔루션 제공업체와 쉽게 통합할 수 있음
친숙한 방식으로 프런트 엔드 테스트를 제공함
WebDriverJS
WebDriverJs는 Selenium의 Json-wire-protocol을 사용하여 브라우저와 상호 작용하는 Selenium의 공식 Javascript 버전임
WebDriverJS는 기본적으로 Selenium WebDriver와 동일한 기능을 수행함
Test Cafe
테스트 카페는 노드입니다. 웹 애플리케이션을 테스트하는 데 사용할 수 있는 Node.js 종단간 무료 오픈 소스 자동화 도구입니다. Windows, MacOS 및 Linux와 같은 널리 사용되는 모든 환경에서 작동합니다. 단일 명령의 설치하기 쉬운 기능을 사용하여 JavaScript 또는 TypeScript로 스크립트를 작성할 수 있습니다.
Lambda Test
가능한 모든 측면에서 웹 제품을 검사할 수 있도록 수많은 신규 및 레거시 모바일 및 데스크탑 브라우저와 OS를 제공하는 크로스 브라우저 테스트 도구
다양한 플랫폼에서 수동 테스트, 자동화 테스트, 지리적 위치 테스트, 사이프러스 테스트를 수행할 수 있으며 테스트 결과 스크린샷을 번거로움 없이 팀과 공유할 수 있음
팀 커뮤니케이션의 디버깅 및 품질 향상을 위해 많은 통합이 제공됨
Katalon Studio
모바일, 데스크톱 API 및 웹 UI 테스트를 제공하는 테스트 자동화 도구
테스트 생성은 다재다능하며 코딩 경험이 있거나 없는 사용자를 위한 이중 편집기 인터페이스와 함께 제공됨
여러 로케이터 전략으로 UI 변경을 완벽하게 조정할 수 있음
객체 탐지기의 불안정성을 처리하기 위해 자가 치유 메커니즘을 제공
각 실행 후 실시간 알림 및 통찰력 있는 그래프로 보고서를 생성할 수 있음
Test Complete
모바일, 웹 및 데스크톱 애플리케이션을 테스트하는 GUI 자동화 도구
비기술 사용자와 기술 사용자 모두 사용할 수 있음
애플리케이션의 품질은 효율성과 규모로 제공됨
코드리스 또는 코드 테스트 생성을 제공
복잡한 물체를 식별하고 뛰어난 물체 인식 기능을 제공
Front End 성능 최적화
이전의 성능 최적화는 서버 측 최적화를 의미했음
대부분의 웹사이트가 대부분 정적이었고 대부분의 처리가 서버 측에서 이루어졌기 때문
그러나 Web 2.0 기술의 시작과 함께 웹 애플리케이션이 더욱 동적으로 변하면서, 클라이언트 측 코드는 성능을 많이 차지하게 되었음
프런트 엔드 성능 최적화하면 뭐가 좋은데?
웹 사이트 테스트에서 서버 병목 현상을 제외하고 클라이언트 측 성능 문제를 찾는 것은 사용자 경험에 쉽게 영향을 미치기 때문에 똑같이 중요
백엔드 성능을 50% 향상시키면 애플리케이션의 전체 성능이 10% 향상되지만, 프런트 엔드 성능을 50% 향상시키면 애플리케이션의 전체 성능이 40% 향상됨
이것은 기본적인 경우이지만 누군가가 애플리케이션에 이름을 제공하는 것을 무시했을 수 있는 작은 극단적인 경우를 다루고 있음
"왜 그렇게 작은 것을 테스트해야 하나?"
당신의 기능의 가능한 결과에 대해 깊이 생각하도록 강요하며, 대부분의 경우 코드에서 이를 커버하는 데 도움이 되는 에지 케이스를 실제로 발견함
코드의 일부는 이 엣지 케이스에 의존할 수 있으며 누군가 와서 중요한 것을 삭제하면 테스트는 이 코드가 중요하며 제거할 수 없다고 경고함
단위 테스트는 종종 작고 단순함
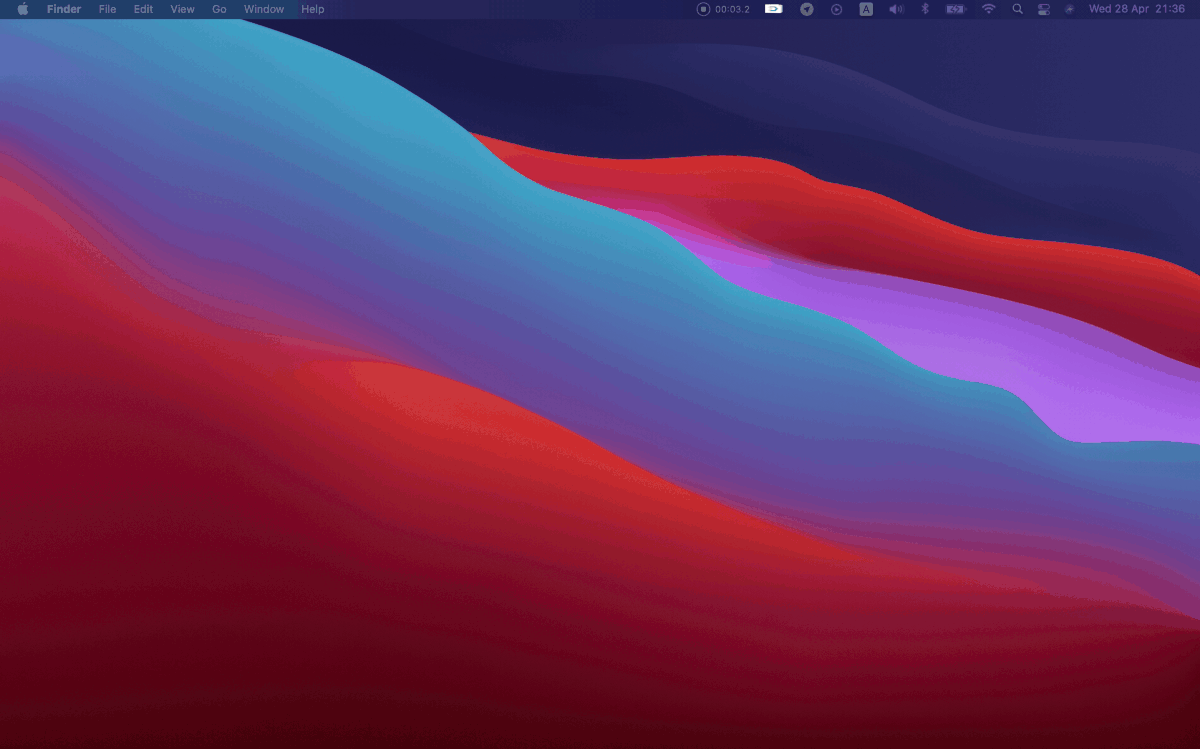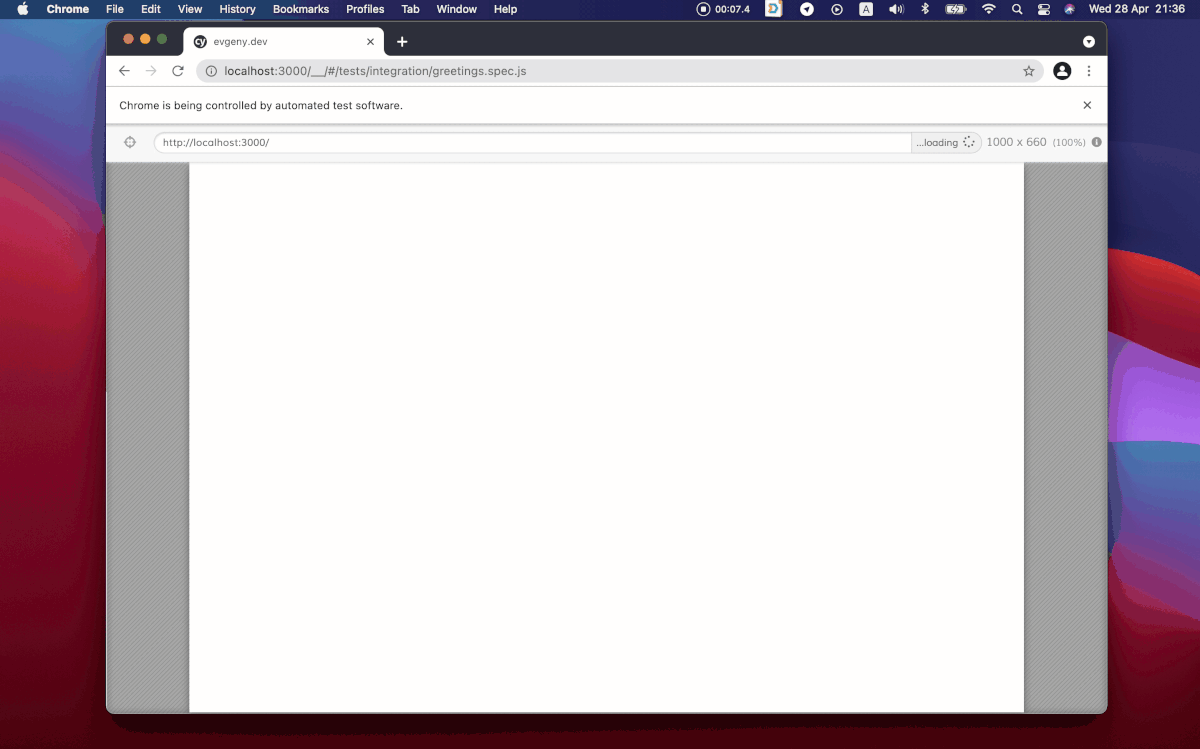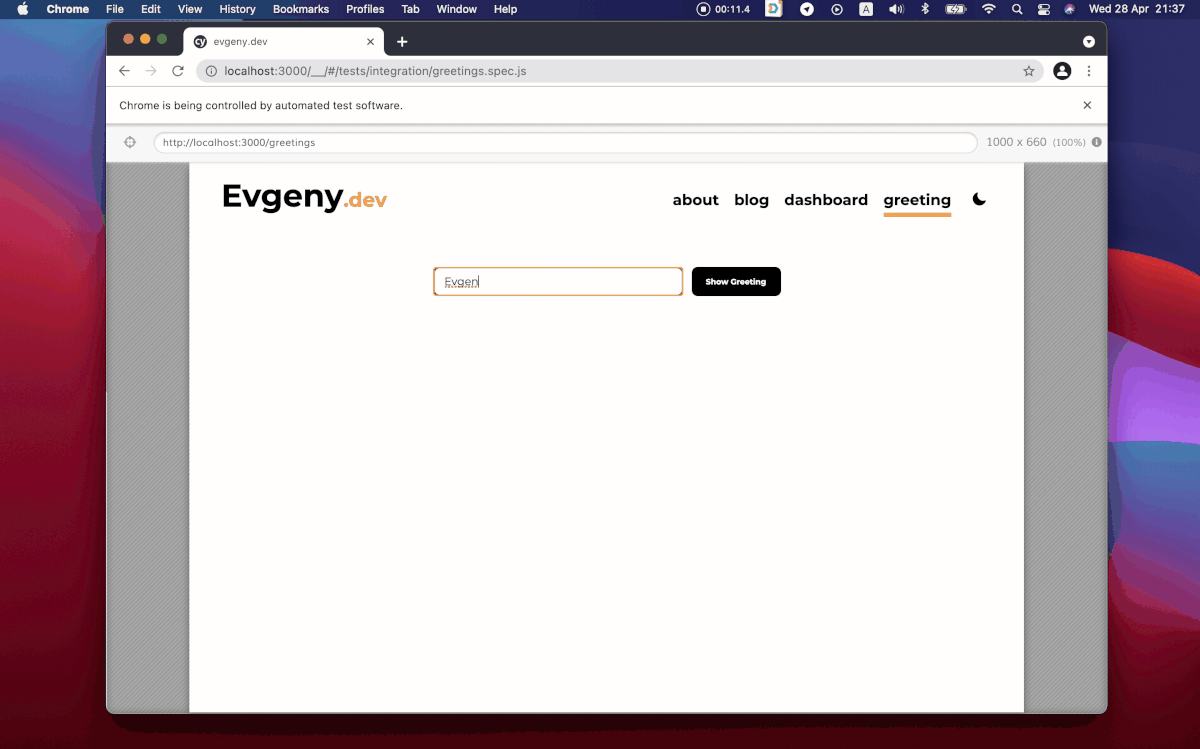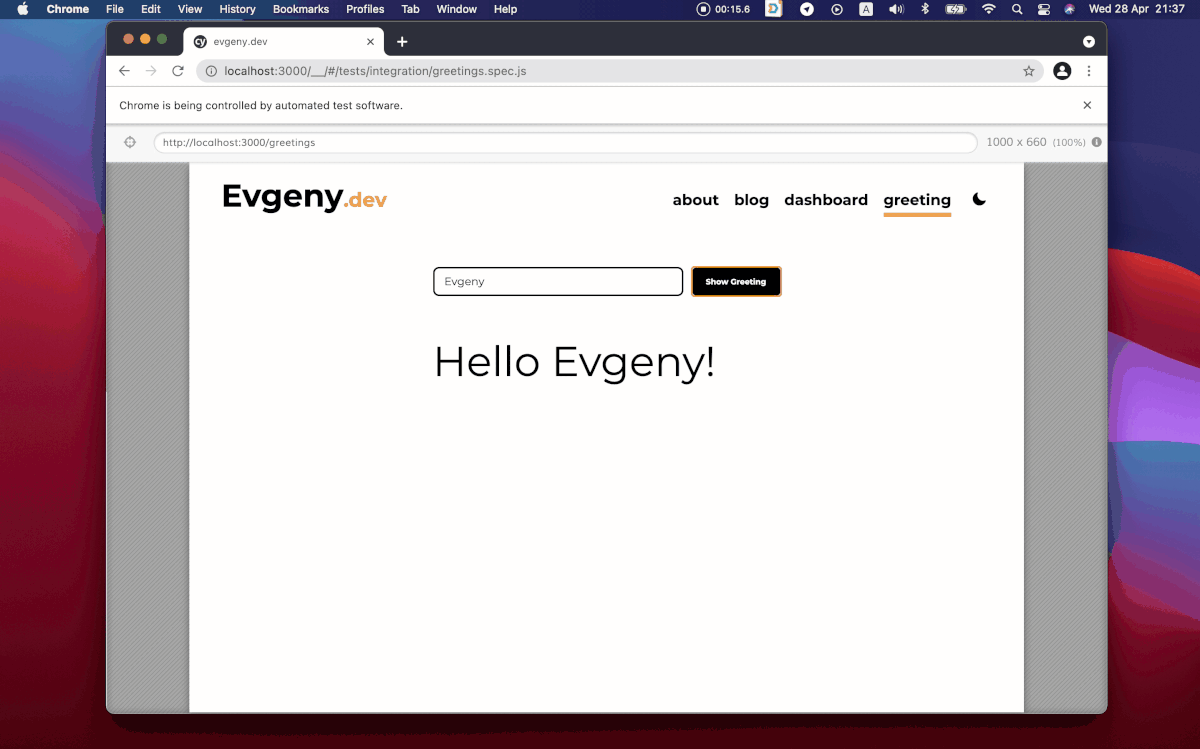
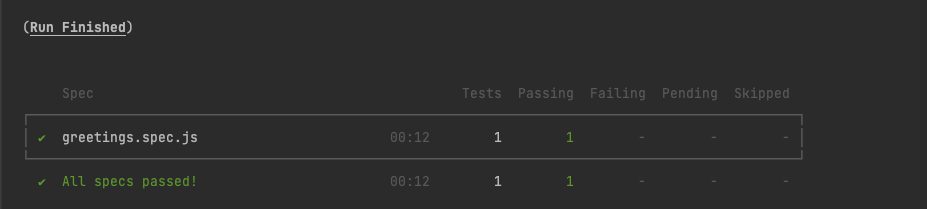
describe("sayHello function", () => {
it("should return the proper greeting when a user doesn't pass a name", () => {
expect(sayHello()).toEqual("Hello human!")
})it("should return the proper greeting with the name passed", () => {
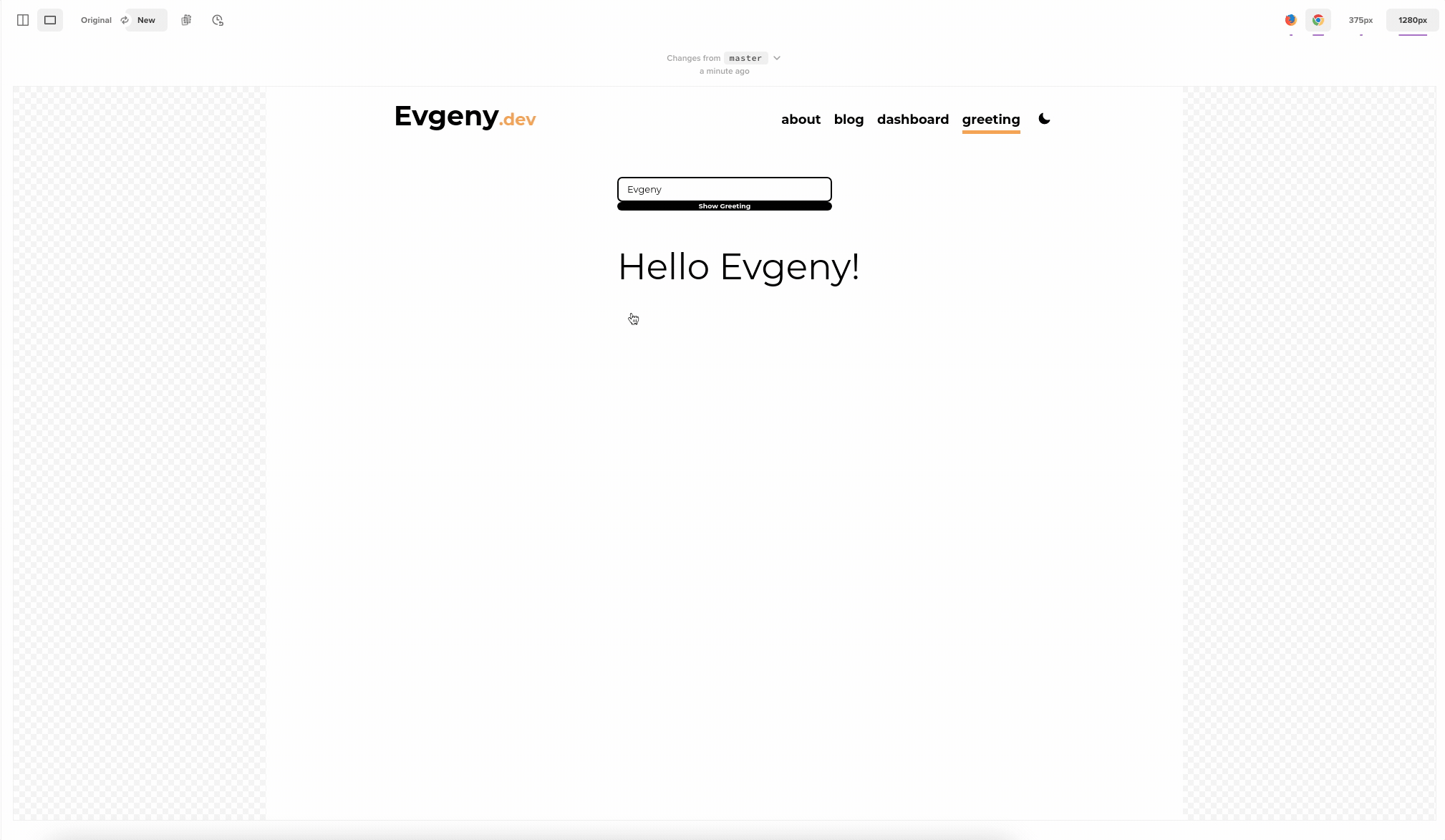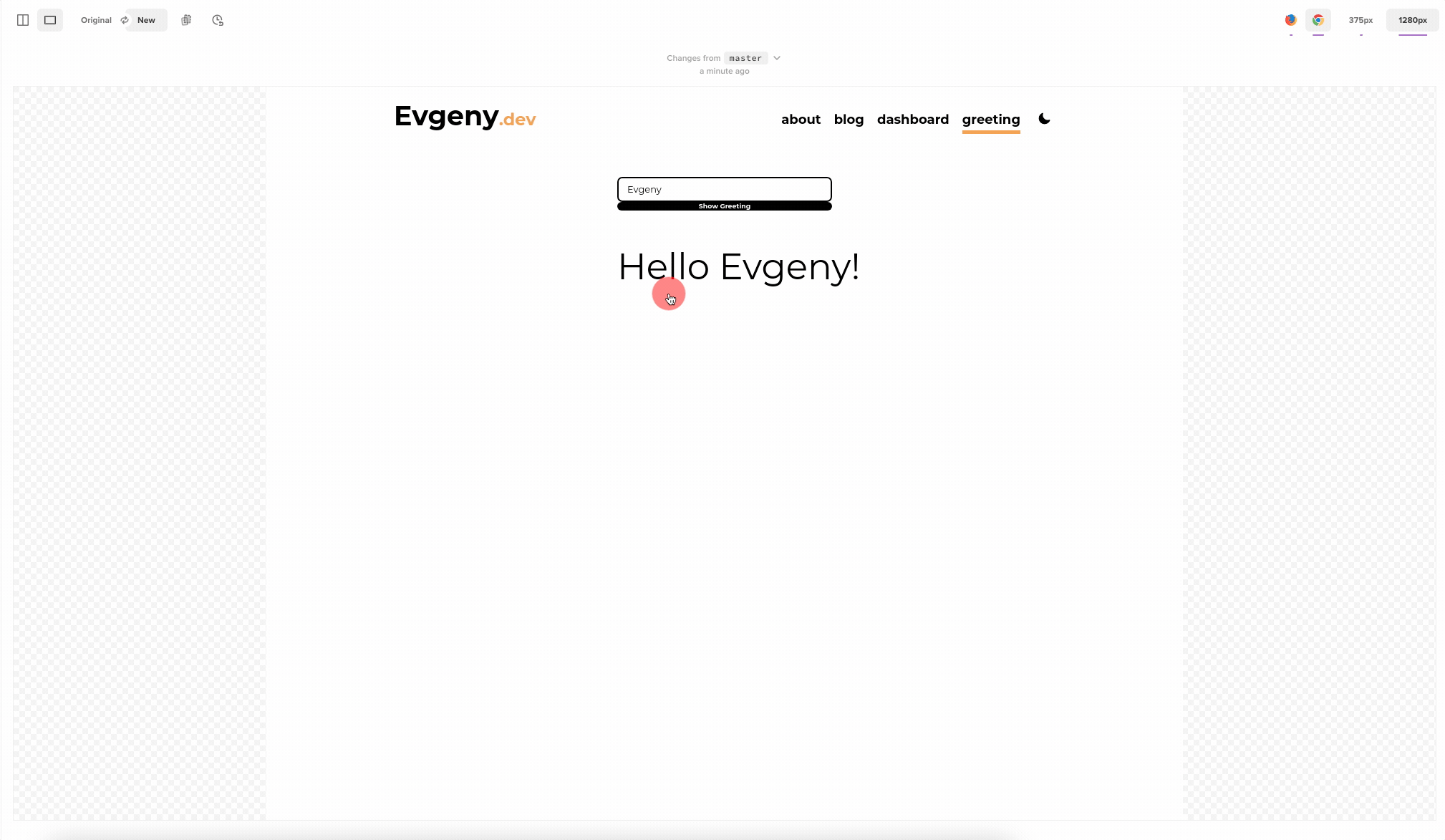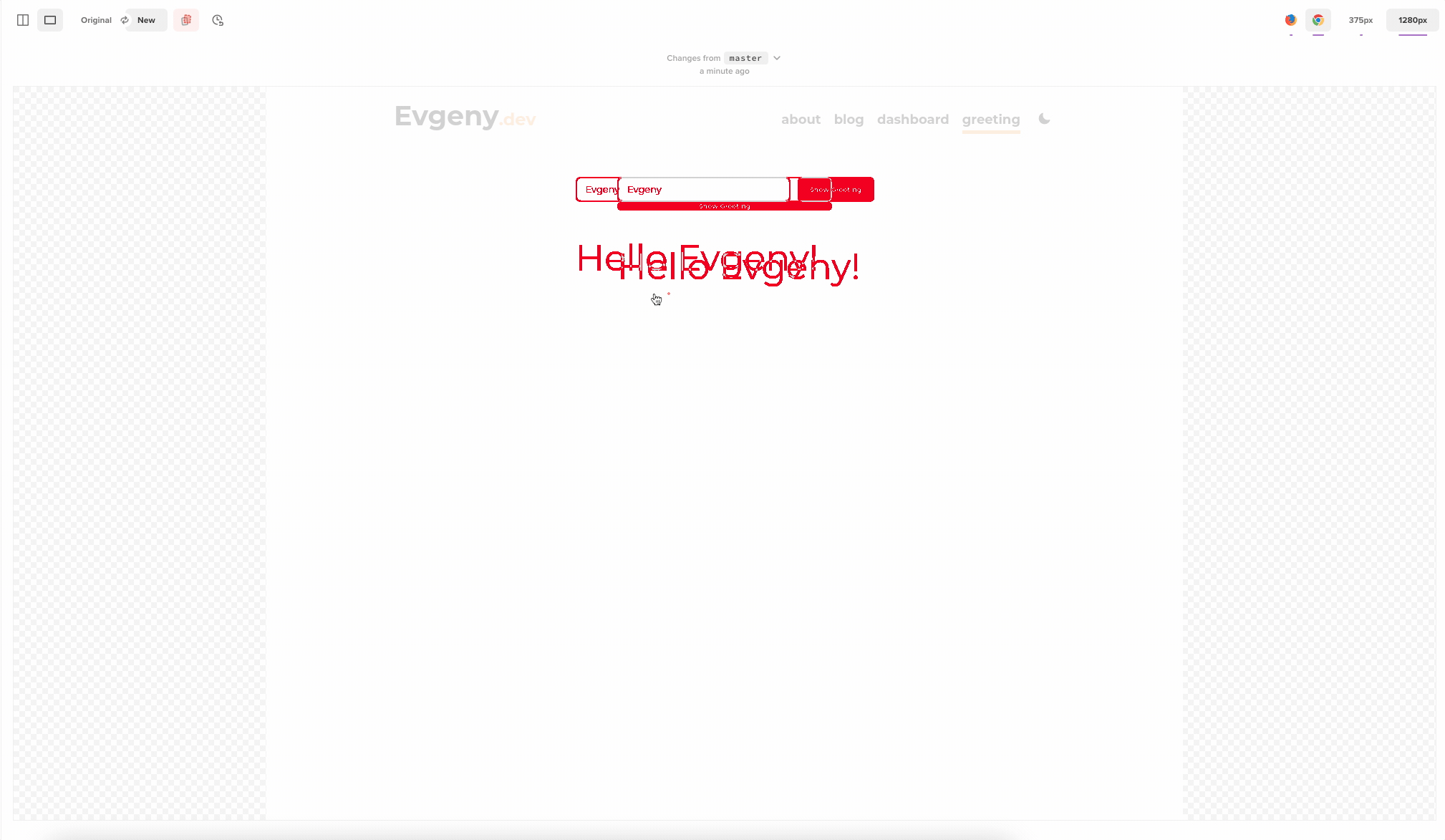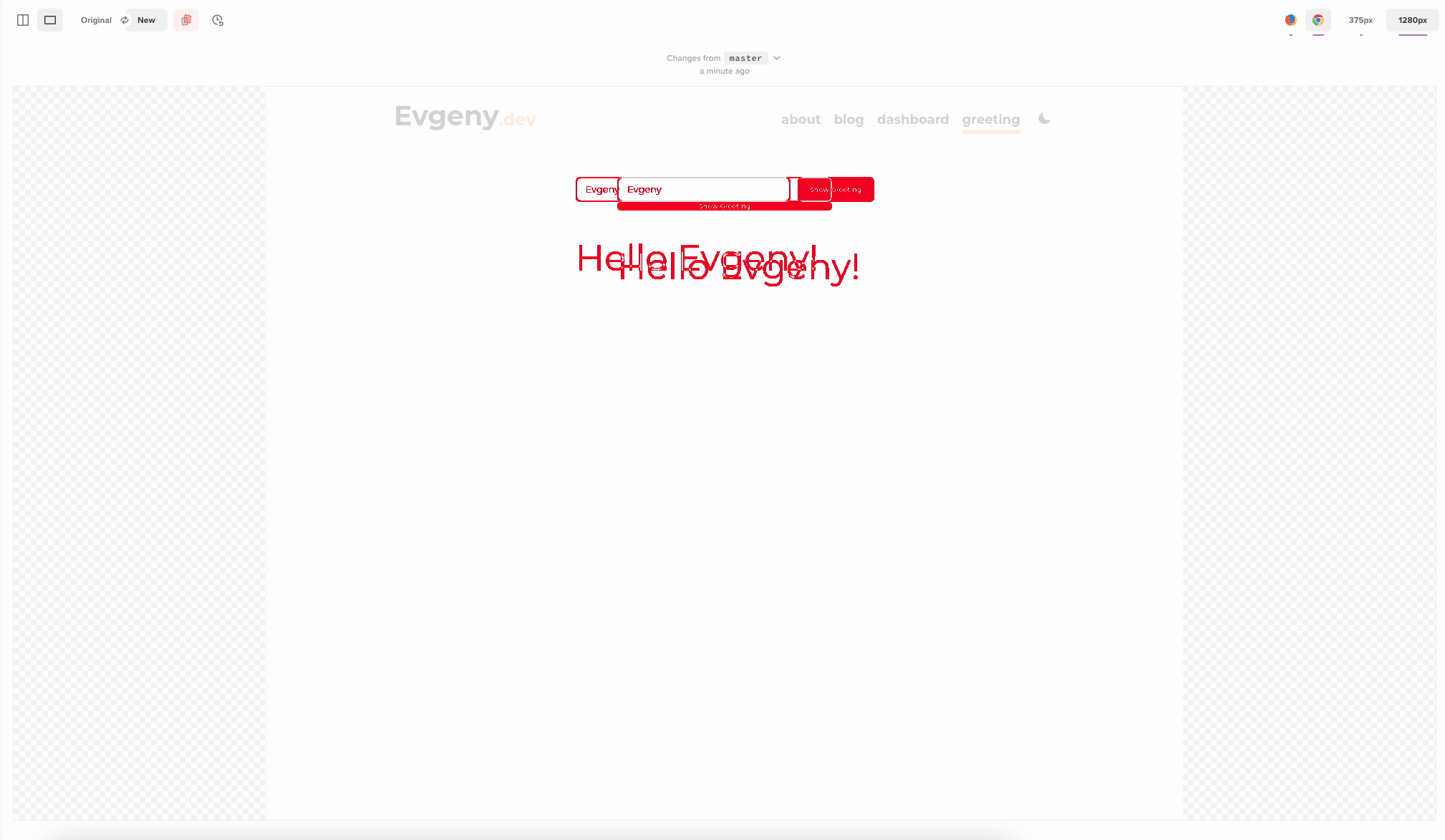
expect(sayHello("Evgeny")).toEqual("Hello Evgeny!")
})
})
describe테스트를 터미널에 인쇄되는 논리 블록 으로 it나눔
가장 중요한 줄은 expect및 toEqual임
이 expect함수는 유효성을 검사하려는 입력을 toEqual수락하고 원하는 출력을 수락함
응용 프로그램을 테스트하는 데 사용할 수 있는 다양한 기능과 메서드가 많이 있음
단위 작성을 위한 라이브러리인 Jest 로 작업하고 있다고 가정해 보았을 때, 위의 예에서 Jest는 sayHello함수를 터미널에 제목으로 표시함
함수 내부의 모든 것은 it단일 테스트로 간주되며 함수 제목 아래의 터미널에 보고되므로 모든 것을 매우 쉽게 읽을 수 있음
Memoization이란 컴퓨터 프로그램이 동일한 계산을 반복해야 할 때, 이전에 계산한 값을 메모리에 저장함으로써 동일한 계산의 반복 수행을 제거하여 프로그램 실행 속도를 빠르게 하는 기술
useMemo, useCallback, React.memo는 모두 이 Memoization을 기반으로 작동
비용이 많이 드는 함수 호출의 결과를 저장하고 동일한 입력이 다시 발생할 때 캐시된 결과를 반환하여 컴퓨터 프로그램 속도를 높이는 데 주로 사용되는 최적화 기술
소프트웨어 시스템의 일부 측면을 보다 효율적으로 작동시키거나 더 적은 리소스를 사용하도록 수정하는 프로세스
2. 최적화와 메모이제이션
구성 요소의 수명 주기에서 React는 업데이트가 이루어질 때 구성 요소를 다시 렌더링함
웹 페이지 하나가 만들어질 때는 위와 같이, DOM Tree의 구성, 레이아웃 잡기, 페인팅하기 등의 다양한 작업이 이루어짐
리랜더링 시에, 레이아웃 및 페인팅 과정을 또 계산해야 할 수 있음
⇒ 그래서 React의 성능을 점검할 때는 컴포넌트 자체의 리랜더링이 불필요하게 반복되고 있지 않은지, 그리고 내부 로직이 쓸데없이 다시 만들어지거나 복잡한 계산을 반복하고 있지는 않은지에 대한 검토가 필요함
React가 구성 요소의 변경 사항을 확인할 때 JavaScript가 동등성 및 얕은 비교(equality and shallow comparisons)를 처리하는 방식으로 인해 의도하지 않거나 예기치 않은 변경 사항을 감지할 수 있고 React 애플리케이션은 이러한 변경으로 인해 불필요하게 재렌더링될 수 있음
⇒ 비용이 많이 드는 작업은 시간, 메모리 또는 처리 비용이 많이 들 수 있어 성능저하가 발생할 수 있으므로 사용자 경험 또한 저하될 수 있음
⇒ React는 이를 개선하기 위해 메모 아이디어를 발표함
⇒ 쓸데없이 같은 계산을 반복하게 하지 않게 할 수 있는 방법은? 결과를 기억하는 것
useMemo
1. 이건 뭐야?
정의?
이전 값을 기억해두었다가 조건에 따라 재활용하여 성능을 최적화 하는 용도로 사용됨 (특정 value를 재사용)
useMemo의 특징은 일단 함수 호출 이후의 return 값이 memoized되며, 두 번째 파라미터인 배열의 요소가 변경될 때마다 첫 번째 파라미터의 callback 함수를 다시 생성하는 방식임
useRef와의 차이
useMemo는 deps가 변경되기 전까지 값을 기억하고, 실행후 값을 보관하는 역할로도 사용
useMemo는 복잡한 함수의 return 값을 기억한다는 점에서 값만 기억하는 useRef와는 다름
useRef는 특정 값을 기억하는 경우, useMemo는 복잡한 함수의 return값을 기억하는 경우에 사용됨
동작방식
초기 렌더링 중에 useMemo(compute,dependencies)계산을 호출하고 계산 결과를 메모한 다음 구성 요소로 반환함
useMemo종속성 중 하나가 변경된 경우에만 메모된 값을 다시 계산하며, 이 최적화는 모든 렌더링에서 비용이 많이 드는 계산을 피하는 데 도움이 됨
다음 렌더링 중에 종속성이 변경되지 않으면 useMemo() 는 컴퓨팅을 호출하지 않고 메모된 값을 반환함
2. 어디에 써?
비용이 많이 드는 계산을 메모화하는 데 사용
여기서 비싸다는 의미는 메모리와 같은 리소스를 많이 사용한다는 것을 의미
3. 주의점은?
종속성 비교로 인한 계산 비용
내부적으로 React의 useMemo Hook은 값을 다시 계산해야 하는지 여부를 결정하기 위해 다시 렌더링할 때마다 종속성 배열의 종속성을 비교해야 하며, 종종 이 비교를 위한 계산은 단순히 값을 다시 계산하는 것보다 비용이 더 많이 들 수 있음 ⇒ useMemo애플리케이션에서 너무 자주 구현 하면 성능이 저하될 수 있음
프로파일링 도구를 사용하여 비용이 많이 드는 성능 문제를 식별할 수 있음
4. 예시를 살펴보자!
useMemo 사용 전
import { useState } from 'react';
export function MyComponent() {
const [number, setNumber] = useState(1);
const [inc, setInc] = useState(0);
const factorialResult = calculateFactorial(number);
const onChange = event => {
setNumber(Number(event.target.value));
};
const onClick = () => setInc(i => i + 1);
return (
<div>
Factorial of the following Number
<input type="number" value={number} onChange={onChange} />
is {factorialResult}
<button onClick={onClick}>Increment</button> <span>{inc}</span>
</div>
);
}
function calculateFactorial(number) {
console.log('calculateFactorial called!');
return number <= 0 ? 1 : number * calculateFactorial(number - 1);
}
입력 값을 변경할 때마다 factorialResult가 계산 'calculateFactorial(number) called!'되어 콘솔에 기록됨
Increment 버튼을 클릭할 때마다 inc상태 값이 업데이트됩니다. 상태 값을 업데이트 하면 다시 렌더링 inc이 트리거됨
<MyComponent /> 가 2.번의 이벤트로 인해, 재렌더링되는 동안 다시 calculateFactorial계산 되어 'calculateFactorial(n) called!'값이 콘솔에 기록됨
⇒ useMemo(()=> calculateFactorial(number), [number]) 으로 React는 계산값을 메모할 수 있음
useMemo 사용 후
import { useState, useMemo } from 'react';
export function MyComponent() {
const [number, setNumber] = useState(1);
const [inc, setInc] = useState(0);
const factorialResult = useMemo(() => calculateFactorial(number) , [number]);
const onChange = event => {
setNumber(Number(event.target.value));
};
const onClick = () => setInc(i => i + 1);
return (
<div>
Factorial of the following Number
<input type="number" value={number} onChange={onChange} />
is {factorialResult}
<button onClick={onClick}>Increment</button> <span>{inc}</span>
</div>
);
}
function calculateFactorial(number) {
console.log('calculateFactorial called!');
return number <= 0 ? 1 : number * calculateFactorial(number - 1);
}
입력(input) 값을 변경할 때마다 'calculateFactorial(n) called!'가 콘솔에 기록되지만, Increment 버튼을 클릭 하면 useMemo 에 의해, 메모된 계산값이 반환되기 때문에, 'calculateFactorial(n) called!' 은 콘솔에 기록되지 않음
useCallback
1. 이건 뭔데?
useCallback은 리액트의 렌더링 성능을 위해서 제공되는 Hook이다.
부모컴포넌트에서 자식컴포넌트에 prop으로 넘겨주는 함수가 있을 때, 부모 컴포넌트가 렌더링 될 때마다 내부적으로 사용된 함수도 새로 생성되어, 자식 컴포넌트에 Prop으로 새로 생성된 함수가 넘겨지게 되면 불필요한 리렌더링이 일어날 수 있다.
useCallback을 사용하여 함수를 memoized 시키면, 종속성 배열의 종속성이 변경되는 경우에만 이 함수가 다시 정의됨
useCallback의 특징
useCallback은 function의 메모리 재할당을 막기위한 수단
여러곳에서 사용되는 컴포넌트가 불필요하게 같은 function을 메모리에 여러번 할당한다면, useCallback을 사용한 최적화가 필요
useCallback은 함수의 결과를 메모리에 저장하는게 아니라, 메모리에 저장된 함수를 같은 컴포넌트들에서 공유하는 개념
2. 언제 써?
함수를 메모하기 위해 사용되며, 부모 구성 요소를 다시 렌더링할 때마다 함수가 다시 초기화되는 것에 대해 걱정하지 않고 다른 구성 요소에 함수를 전달할 때 이미 약간의 성능 향상이 있음
useCallback은 React.Memo와 함께 사용할 때 특히 유용함
컴포넌트가 랜더링 될 때마다 내부에 선언되어 있던 표현식이 다시 선언되어 사용됨. 이 때, 컴포넌트 내부에 있는 함수는 변동이 없음에도 컴포넌트가 리랜더링 될 때마다 다시 선언됨. ⇒ 이런 경우에 useCallback을 import해서 사용하던 함수의 실행문을 넣어주면 랜더링 될 때마다 선언되는 것을 피할 수 있고 의존성 배열에 요소를 추가하면 해당 값이 변경될 때 재선언 가능.
또한, 상위컴포넌트의 함수가 매번 재선언되면, 내용이 같다고 하더라도 하위컴포넌트는 넘겨받는 함수가 달라졌다고 인식함. ⇒ 따라서 하위컴포넌트가 React.memo() 등으로 최적화 되어있고, 그 하위 컴포넌트에게 callback 함수를 props로 넘길 경우에, 상위컴포넌트에서 useCallback으로 선언하는 것이 최적화에 도움됨.
React.memo()로 함수형 컴포넌트 자체를 감싸면 넘겨 받는 props가 변경되지 않았을 때는 상위 컴포넌트가 메모리제이션된 함수형 컴포넌트(이전에 렌더링된 결과)를 사용하게 됨.
3. 주의점은?
React의 useCallback Hook은 함수를 재정의해야 하는지 여부를 결정하기 위해 다시 렌더링할 때마다 종속성 배열의 종속성을 비교해야 함 ⇒ 종종 이 비교를 위한 계산은 단순히 함수를 재정의하는 것보다 더 비쌀 수 있음 ⇒ 그렇기 때문에 프로파일러 API 를 사용하여 사용 여부를 확인하는 것이 좋습니다.
const MemoisedItem = React.memo(Item);
const List = () => {
**// this HAS TO be memoised, otherwise `React.memo` for the Item is useless**
const onClick = () => {console.log('click!')};
return <MemoisedItem onClick={onClick} country="Austria" />
}
useCallback(() => { cookies.clear() }, []) 는 항상 같은 함수 인스턴스를 반환하고, MemoizedLogout의 메모이제이션이 정상적으로 동작하도록 수정되었음
컴포넌트가 hooks(useMemo, useCallback or useEffect)에 dependency로 callback을 받을 때
const Item = ({ onClick }) => {
useEffect(() => {
// some heavy calculation here
const data = ...
onClick(data);
**// if onClick is not memoised, this will be triggered on every single render**
}, [onClick])
return <div>something</div>
}
const List = () => {
// this HAS TO be memoised, otherwise `useEffect` in Item above
// will be triggered on every single re-render
const onClick = () => {console.log('click!')};
return <Item onClick={onClick} country="Austria" />
}
나쁜 사용 사례
import { useCallback } from 'react';
function MyComponent() {
// Contrived use of `useCallback()`
const handleClick = useCallback(() => {
// handle the click event
}, []);
return <MyChild onClick={handleClick} />;
}
function MyChild ({ onClick }) {
return <button onClick={onClick}>I am a child</button>;
}
첫 번째 문제는 렌더링 useCallback()할 때마다 후크가 호출 된다는 것 : 그것은 이미 렌더링 성능을 감소시킴
두 번째 문제는 사용 useCallback()이 코드 복잡성을 증가시키는 것 : useCallback(..., deps) 의 deps와 memoized 콜백 내에서 사용 중인 것과 동기화 deps를 유지해야 함.
useCallback()의미가 있을까? : <MyChild>구성 요소가 가볍고 다시 렌더링해도 성능 문제가 발생하지 않기 때문일 가능성이 높음
⇒ 결론적으로 최적화를 하지 않는 것보다 최적화 비용이 더 많이 듬
React.memo
1. 이게 뭔데?
UI 성능을 증가시키기 위해, React는 고차 컴포넌트(Higher Order Component, HOC) React.memo()를 제공
고차 컴포넌트
고차 컴포넌트(HOC, Higher Order Component)는 컴포넌트 로직을 재사용하기 위한 React의 고급 기술
고차 컴포넌트(HOC)는 React API의 일부가 아니며, React의 구성적 특성에서 나오는 패턴
구체적으로, 고차 컴포넌트는 컴포넌트를 가져와 새 컴포넌트를 반환하는 함수
렌더링 결과를 메모이징(Memoizing)함으로써, 불필요한 리렌더링을 건너뜀
컴포넌트가 동일한 props로 동일한 결과를 렌더링해낸다면, React.memo를 호출하고 결과를 메모이징(Memoizing)하도록 래핑하여 경우에 따라 성능을 향상시킬 수 있음 ⇒ React.memo는 컴포넌트를 렌더링하지 않고 마지막으로 렌더링된 결과를 재사용함
React.memo는 props 변화에만 영향을 주며, React.memo로 감싸진 함수 컴포넌트 구현에 useState, useReducer 또는 useContext 훅을 사용한다면, 여전히 state나 context가 변할 때 다시 렌더링됨
state count1이 변경되었을 때, state 변경이 없었던 count2를 참조하는 CountButton 컴포넌트는 리렌더리 되지 않아야 함(React.memo로 래핑되었다는 가정)
만약 increment2 함수에 useCallback이 없었다면, DualCounter 컴포넌트는 state의 변경으로 인해 re-rendering 될 것이고, increment1과 increment2 함수 모두 새로 생성되어 2개의 CountButton 컴포넌트는 모두 re-rendering 될 것
하지만 increment1, increment2 함수에 useCallback을 사용함으로써 두개의 함수는 재 생성이 되지 않고 (종속배열도 비어있음) 변경된 count1을 참조하는 CountButton만 re-rendering 되게 됨
4. 예시로 알아보자!
같은 props로 렌더링이 자주 일어나는 컴퍼넌트에 사용하기 좋음
React.memo()를 사용하기 가장 좋은 케이스는 함수형 컴퍼넌트가 같은 props로 자주 렌더링 될거라 예상될 때이다.
일반적으로 부모 컴퍼넌트에 의해 하위 컴퍼넌트가 같은 props로 리렌더링 될 때가 있음
Movie의 부모 컴퍼넌트인 실시간으로 업데이트되는 영화 조회수를 나타내는 MovieViewsRealtime 컴퍼넌트가 있다고 하자.
function MovieViewsRealtime({ title, releaseDate, views }) {
return (
<div>
<Movie title={title} releaseDate={releaseDate} />
Movie views: {views}
</div>
);
}
이 어플리케이션은 주기적(매초)으로 서버에서 데이터를 폴링(Polling)해서 MovieViewsRealtime 컴퍼넌트의 views를 업데이트함
// Initial render
<MovieViewsRealtime views={0} title="Forrest Gump" releaseDate="June 23, 1994"/>// After 1 second, views is 10
<MovieViewsRealtime views={10} title="Forrest Gump" releaseDate="June 23, 1994"/>// After 2 seconds, views is 25
<MovieViewsRealtime views={25} title="Forrest Gump" releaseDate="June 23, 1994"/>// etc
views가 새로운 숫자가 업데이트 될 때 마다 MoviewViewsRealtime 컴퍼넌트 또한 리렌더링 되며, Movie 컴퍼넌트 또한 title이나 releaseData가 같음에도 불구하고 리렌더링 됨
이때가 Movie 컴퍼넌트에 메모이제이션을 적용할 적절한 케이스임
MovieViewsRealtime에 메모이징된 컴퍼넌트인 MemoizedMovie를 대신 사용해 성능을 향상해보자.
function MovieViewsRealtime({ title, releaseDate, views }) {
return (
<div>
<MemoizedMovie title={title} releaseDate={releaseDate} />
Movie views: {views}
</div>
);
}
title 혹은 releaseDate props가 같다면, React는 MemoizedMovie를 리렌더링 하지 않을 것이다. 이렇게 MovieViewsRealtime 컴퍼넌트의 성능을 향상할 수 있음
React.memo vs. useMemo vs. useCallback
1. 공통점
공통점
React.memo, useMemo, useCallback은 모두 불필요한 렌더링 또는 연산을 제어하는 용도로 성능 최적화에 그 목적이 있음
재렌더링 사이의 메모이제이션임
전달하려는 항목이 새로운 참조여도 상관없다면, 사용하지 말아야 한다. 매번 새로운 참조여도 상관없는데, 새로운 참조라면 메모이제이션하는 것이 의미가 없음
useMemo와 useCallback을 사용해야 하는 경우
하위트리에 많은 Consumer가 있는 값을 Context Provider에 전달해야 하는 경우 useMemo를 사용하는 것이 좋음 <ProductContext.Provider value={{id, name}} >의 경우, 어떤 이유로든 해당 컴포넌트가 리렌더링 된다면 idname이 동일하더라도 매번 새로운 참조를 만들어 죄다 리렌더링 될 것
계산 비용이 많이 들고, 사용자의 입력 값이 렌더링 이후로도 참조적으로 동일할 가능성이 높은 경우, useMemo를 사용하는 것이 좋음
매우 큰 리액트 트리 구조 내에서, 부모가 리렌더링 되었을 때 이에 다른 렌더링 전파를 막고 싶을 때 사용하자. 자식 컴포넌트가 React.memoReact.PureComponent일 경우, 메모이제이션된 props를 사용하게되면 딱 필요한 부분만 리렌더링 될 것
사용팁
React DevTools Profiler를 사용하면 컴포넌트의 리렌더링 속도가 느린 경우, 상태 변경이 일어났을 때 얼마나 렌더링 시간이 걸렸는지 조사할 수 있음
이렇게 하면 거대한 계단식 리렌더링을 방지하기 위해 React.memo를 사용할 위치를 찾을 수 있고, 필요한 경우 useCallbackuseMemo를 사용하여 상태변경을 더 효율적으로 만들 수 있음
2. 차이점
React.memo는 HOC이고, useMemo와 useCallback은 hook
React.memo는 HOC이기 때문에 클래스형 컴포넌트, 함수형 컴포넌트 모두 사용 가능하지만, useMemo는 hook이기 때문에 함수형 컴포넌트 안에서만 사용 가능
useMemo는 함수의 연산량이 많을때 이전 결과값을 재사용하는 목적이고, useCallback은 함수가 재생성 되는것을 방지하기 위한 목적(React.memo와 useMemo의 차이는 어디에 활용되는가임)
React.memo의 경우에는 컴포넌트를 받아 컴포넌트를 반환한다.
useMemo의 경우에는 값을 계산하는 과정을 최적화해 값을 반환받음(컴포넌트도 값이기에 useMemo 안에 넣을 수 있음)
3. 주의점
일부 개발자가 흔히 저지르는 실수는 성능 문제를 방지하기 위해 필요하지 않은 경우에도 이러한 후크(및 기타 최적화 기술)를 사용하는 것임
이는 코드를 더 복잡하게 만들고(따라서 유지 관리하기 더 어렵게 만들고) 경우에 따라 성능이 더 나빠지기 때문에 권장되지 않음
성능 문제를 찾은 후 이러한 기술을 적용해야 함
원하는 만큼 빠르게 실행되지 않는 경우 병목 현상이 있는 부분을 조사하고 해당 부분을 최적화가 필요
useCallback을 사용하여 접근하는 좋은 방법은 능동적이기보다는 반응적으로 접근하는 것임
즉, 구성 요소에 따라 조급한 성능 최적화가 아니라 분명히 필요할 때 사용하는 것이 중요함
관심 있는 구성 요소를 클릭하면 특정 구성 요소가 다시 렌더링된 이유를 정확하게 확인할 수 있음.
React 프로파일러에는 다시 렌더링하는 구성 요소를 강조 표시할 수 있는 옵션이 있음
이 설정을 사용하면 다시 렌더링하는 구성 요소 주위에 녹색 사각형이 깜박이는 것을 볼 수 있고 이를 통해 상태 업데이트가 얼마나 광범위한지 확인할 수 있고 일부 요소가 재렌더링을 성공적으로 피하는지 테스트할 수 있음
개인적으로 느낀 점
일전에 React를 사용하며, 부모 Component에서 자식 Component로 callback을 Prop으로 내려줬는데 의도치않게 너무 많은 랜더링이 일어나는 이슈를 겪은 적이 있다.
그 때, useCallback으로 해결한 경험이 있어서 그 이후 useCallback을 남발하게 되었던 것 같다.
메모이제이션이라는 것이 어딘가에 저장을 하는 만큼(메모리) 결코 공짜가 아니라는 생각이 들었고 과연 나는 useCallback을 효율적으로 사용하고 있는가라는 의문이 들었다.
관련하여 찾다보니, React의 다른 메모이제이션 훅, HOC에 대해서도 찾을 수 있었다.
역시, 메모이제이션 기능은 공짜가 아니었고 오히려 이러한 성급한 최적화 시도가 성능을 더 저하시킬 수 있다는 것을 확인하였다.
useCallback의 경우에도 꼭 필요한 경우(React.memo로 래핑한 자식 컴포넌트에 callback을 넘겨주는 경우, 자식 컴포넌트로 내려가는 callback으로 인해, 자식의 useEffect가 의도치 않게 계속 시행되는 경우 등)와 사용에 대한 근거 없이는 사용을 자제해야겠다는 생각을 했다.
이전에 너무 많은 랜더링이 일어난 상황이 현재는 잘 기억나진 않지만, 아마도 useEffect 종속성 문제와 겹치면서 일어난 참사이지 않았을까 생각이 든다.
당시 React.memo를 사용하는 상황은 아니었기 때문에 굳이 useCallback을 쓰지 않고 해결할 수 있는 방법도 있지 않았을까 생각이 들고 상황상 여의치 않다면 이전에 해결한 방법과 동일하게 useCallback을 결국 써야했을 것 같다.
부탁드리는 사항
혹시 잘못된 내용이나, 인용/차용 등에 있어 문제의 소지가 되는 내용이 있다면 언제든 알려주시면 큰 도움이 될 것 같습니다!
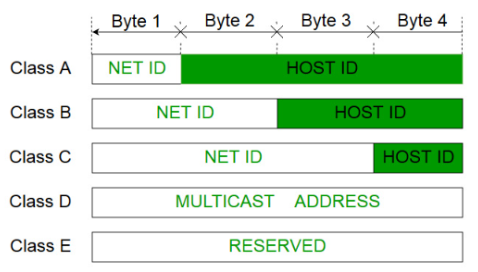
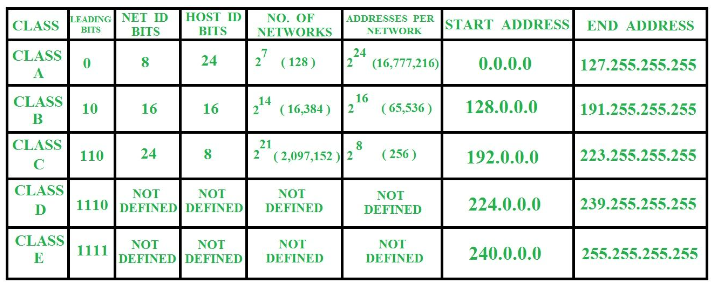
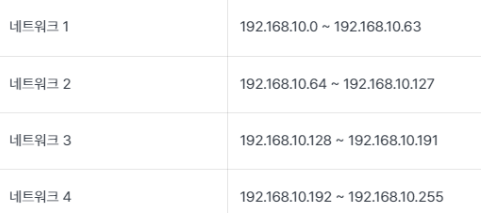
만일 서브네팅을 추가적으로 더 해야 되면 /24를 증가시켜 /25로 표기해 제공 해주면 되고, 반대로 슈퍼네팅을 해야된다면 /24를 감소시켜 /23으로 표기해 제공해주면 됨
이진 배수를 통해 효율적으로 주소 공간 할당 가능
클래스 불균형 제거를 통해, 주소 공간의 일부를 널리 사용할 수 있음
단점
클래스를 기반으로 하는 이전 시스템의 주요 이점은 단순성이었음(첫 번째 옥텟을 보고 IP 주소의 몇 비트가 네트워크 ID를 나타내고 호스트 ID가 몇 비트인지 결정할 수 있었음)
CIDR의 주요 단점은 복잡성임
3. DHCP
DHCP(Dynamic Host Configuration Protocol)?
네트워크의 각 호스트가 효율적으로 통신할 수 있도록 IP 주소 및 기타 정보를 동적으로 할당하는 데 사용되는 네트워크 관리 프로토콜
DHCP는 네트워크 관리자의 작업을 용이하게 하는 IP 주소 할당을 자동화하고 중앙에서 관리
인터넷 프로토콜(IP) 호스트에 해당 IP 주소와 서브넷 마스크 및 기본 게이트웨이와 같은 기타 관련 구성 정보를 자동으로 제공하는 클라이언트/서버 프로토콜
DHCP는 IP 주소 외에도 서브넷 마스크, 기본 게이트웨이 및 DNS(Domain Name Server) 주소 및 기타 구성을 호스트에 할당하여 네트워크 관리자의 작업을 보다 쉽게 만들어 줌
DNS, NTP와 같은 네트워크 서비스 외에도, UDP 또는 TCP 기반의 모든 통신 프로토콜을 사용할 수 있음
DHCP 서버는 다른 IP 네트워크와 통신할 수 있도록 네트워크의 각 장치에 IP 주소 및 기타 네트워크 구성 매개변수를 동적으로 할당함
DHCP는 BOOTP라고 하는 이전 프로토콜의 향상된 기능임
DHCP 왜 쓰는데?
운영 작업 감소
네트워크 관리자는 더 이상 네트워크를 사용하기 전에 각 클라이언트를 수동으로 구성할 필요가 없음
중복되거나 잘못된 IP 할당이 없으므로 IP 주소 충돌이 없음
TCP/IP 기반 네트워크의 모든 장치에는 네트워크와 해당 리소스에 액세스할 수 있는 고유한 유니캐스트 IP 주소가 있어야 함
DHCP가 없으면 한 서브넷에서 다른 서브넷으로 이동하는 새 컴퓨터 또는 컴퓨터의 IP 주소를 수동으로 구성해야 함
네트워크에서 제거된 컴퓨터의 IP 주소는 수동으로 회수해야 함 DHCP를 사용하면 이 전체 프로세스가 중앙에서 자동화되고 관리됨
IP 주소 지정 계획이 최적화됨.
더 이상 사용되지 않는 주소가 해제되고 연결하는 새 클라이언트에서 사용 가능
IP 주소는 고정(영구 할당)이 아닌 동적(임대)이므로 더 이상 사용하지 않는 주소는 재할당을 위해 자동으로 풀로 반환됨
사용자 이동성을 쉽게 관리할 수 있음
관리자는 네트워크 액세스 포인트가 변경될 때 클라이언트를 수동으로 재구성할 필요가 없음
무선 네트워크의 다른 위치로 이동하는 휴대용 장치와 같이 자주
업데이트해야 하는 클라이언트의 IP 주소 변경을 효율적으로 처리
DHCP의 구성 요소
DHCP 서버
일반적으로 네트워크 구성 정보를 보유하는 서버 또는 라우터
DHCP 클라이언트
다른 컴퓨터나 모바일과 마찬가지로 서버에서 구성 정보를 가져오는 끝점
DHCP 릴레이 에이전트(DHCP 패킷이 라우터를 통해 이동할 수 없기 때문에, DHCP 서버가 모든 네트워크의 요청을 처리할 수 있도록 릴레이 에이전트가 필요)
여러 LAN에 대해 하나의 DHCP 서버만 있는 경우 모든 네트워크에 있는 DHCP 릴레이 에이전트가 DHCP 요청을 서버로 전달
IP 주소 풀
클라이언트에 할당할 수 있는 IP 주소 목록을 포함
서브넷 마스크
현재 존재하는 네트워크를 호스트에게 알려줌
임대 시간
클라이언트가 IP 주소를 사용할 수 있는 시간임. 이 시간이 지나면 클라이언트는 IP 주소를 갱신해야 함.
게이트웨이 주소
게이트웨이 주소는 호스트가 게이트웨이가 인터넷에 연결할 위치를 알려줌.
DHCP는 어떻게 동작할까?
기본 흐름
(요약) 응용 프로그램 계층에서 작동하여 IP 주소를 클라이언트에 동적으로 할당하며 이는 DHCP 트랜잭션 또는 DHCP 대화라고 하는 일련의 메시지 교환을 통해 발생
DHCP 서버가 관리자의 정책에 따라 구성 데이터를 요청하는 클라이언트에 전달
요청된 공통 네트워크 매개변수( " DHCP 옵션 " )에는 서브넷 마스크, 라우터, 도메인 이름 서버, 호스트 이름 및 도메인 이름이 포함됨
요청하는 클라이언트는 네트워크에 가입할 때 IP 주소가 없으므로 요청을 브로드캐스트함
⇒ 따라서 프로토콜은 IP 통신의 초기 단계에서 사용됨
이러한 동적 프로토콜이 IP 주소를 가져오는 데 사용되지 않는 경우 클라이언트는 일반적으로 "고정 IP 주소"라고 하는 미리 정의된 IP 주소를 사용해야 함.
이 주소는 구성 파일 또는 특정 명령으로 클라이언트 네트워크 인터페이스에서 수동으로 구성됩니다.
DHCP 동작 예제
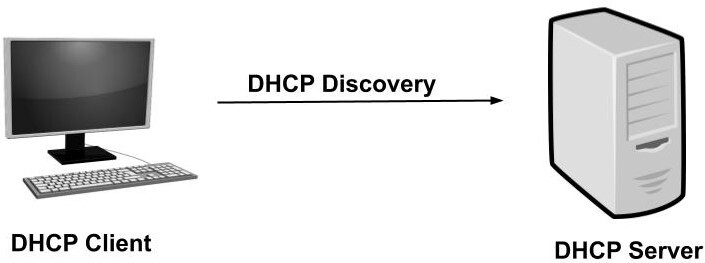
DHCP 검색 DHCP 클라이언트는 DHCP 서버를 검색하기 위해 메시지를 브로드캐스트함 클라이언트 컴퓨터는 기본 브로드캐스트 목적지(255.255.255.255) 또는 설정된 특수 서브넷 브로드캐스트 주소와 함께 패킷을 보냄
255.255.255.255 : “현재 네트워크” 로서, 이 주소를 사용하면 연결된 네트워크에 브로드캐스트 패킷을 보낼 수 있음.
DHCP Offer:
DHCP 서버가 DHCP Discover 메시지를 수신하면 클라이언트에게 DHCP 제안 메시지를 전송하여 클라이언트에게 IP 주소(IP 주소 풀 형식)를 제안함 이 DHCP 제안 메시지에는 DHCP 클라이언트에 대해 제안된 IP 주소, 서버의 IP 주소, 클라이언트의 MAC 주소, 서브넷 마스크, 기본 게이트웨이, DNS 주소 및 임대 정보가 포함됨
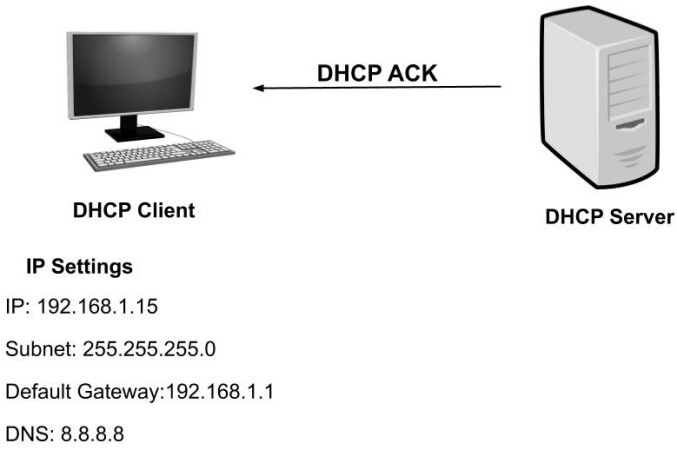
DHCP 클라이언트에 대해 제안된 IP 주소 : 192.168.1.11
네트워크를 식별하기 위한 서브넷 마스크 : 255.255.255.0
서브넷의 기본 게이트웨이 IP : 192.168.1.1
이름 번역을 위한 DNS 서버의 IP : 8.8.8.8
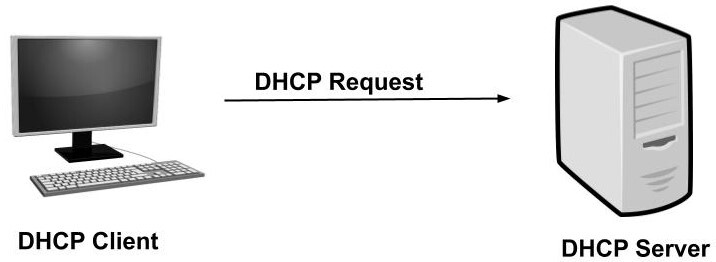
DHCP 요청그러나 클라이언트는 하나의 DHCP 제안만 수락나머지 DHCP 서버에서 제공되는 다른 모든 IP 주소는 철회되고 사용 가능한 IP 주소 풀로 반환됨
제안에 대한 응답으로 클라이언트는 DHCP 서버 중 하나에서 제안된 주소를 요청하는 DHCP 요청을 보냄
대부분의 경우 클라이언트는 네트워크에 많은 DHCP 서버가 있기 때문에(결함에 대한 용인을 제공하므로), 한 서버의 IP 주소 지정이 실패하면 다른 서버가 백업을 제공할 수 있음
DHCP Acknowledgement서버는 클라이언트가 요청할 수 있는 다른 설정을 보낼 수도 있음
이 단계에서 IP 구성이 완료되고 클라이언트는 새 IP 설정을 사용할 수 있음
그런 다음 서버는 클라이언트에 대한 DHCP 임대를 확인하는 Acknowledgement를 클라이언트에 보냄
DHCP는 장점만 있나? 단점은 뭐지?
보안 위험성 DHCP 서버에는 클라이언트 인증을 위한 보안 메커니즘이 없으므로 모든 새 클라이언트가 네트워크에 참여할 수 있음 ⇒ 이는 승인되지 않은 클라이언트에 IP 주소가 부여되고 승인되지 않은 클라이언트로부터 IP 주소가 고갈되는 것과 같은 보안 위험이 있음
실패의 Single Point가 될 수 있음 네트워크에 DHCP 서버가 하나만 있는 경우 DHCP 서버는 실패의 Single Point가 될 수 있음
4. NAT(Network Address Translation)
NAT는 네트워크 주소 변환 을 나타냄
NAT의 개념은 여러 장치가 단일 공용 주소를 통해 인터넷에 액세스할 수 있도록 하는 것임
이를 위해서는 사설 IP 주소를 공인 IP 주소로 변환해야 함 ⇒ 주어진 개인 IP 주소 세트를 게이트웨이 장치에 연결된 단일 공용 IP 주소로 변환함
로컬 호스트에 인터넷 액세스를 제공하기 위해 하나 이상의 로컬 IP 주소를 하나 이상의 글로벌 IP 주소로 또는 그 반대로 변환하는 프로세스임즉, 대상으로 라우팅될 패킷에서 호스트의 포트 번호를 다른 포트 번호로 마스킹하고 NAT 테이블에 해당하는 IP 주소 및 포트 번호 항목을 만듦.
또한 포트 번호 변환을 수행함
NAT는 일반적으로 라우터 또는 방화벽에서 작동
일반적으로 경계 라우터가 NAT용으로 구성됨패킷이 로컬(내부) 네트워크 외부를 통과하면 NAT는 해당 로컬(개인) IP 주소를 글로벌(공용) IP 주소로 변환하고 패킷이 로컬 네트워크에 들어오면 글로벌(공용) IP 주소가 로컬(사설) IP 주소로 변환됨
NAT에 주소가 부족한 경우, 즉 구성된 풀에 주소가 남아 있지 않으면 패킷이 삭제되고 ICMP(Internet Control Message Protocol) 호스트에 연결할 수 없는 패킷이 대상으로 전송됨
즉, 로컬(내부) 네트워크에 하나의 인터페이스가 있고 글로벌(외부) 네트워크에 하나의 인터페이스가 있는 라우터.
예를 들어, 조직의 홈 모뎀 또는 방화벽 장치임그러나 문제는 사설 IP 주소를 가진 장치가 있는 사설 네트워크가 있을 때 대상 서버가 사설 IP 범위로 응답을 라우팅할 수 없기 때문에 트래픽을 공용 인터넷으로 라우팅할 수 없다는 것또한, 사설 네트워크를 외부 네트워크로부터 안전하게 보호할 수 있음
⇒ 여기에서 NAT이 이용됨. 공용 주소로 ISP에 연결된 가정이나 조직의 게이트웨이 장치가 Nating을 수행함. AWS, Azure 또는 Google 클라우드와 같은 클라우드 플랫폼의 경우 NAT 게이트웨이는 프라이빗 서브넷의 서버가 외부 세계와 통신할 수 있도록 퍼블릭 서브넷에 배포됨
IPV4 고갈 문제를 해결하기 위해 사설 IP 범위가 도입되었으며 조직은 수만 대의 컴퓨터와 서버에 대해 사설 IP 범위를 사용할 수 있었음
NAT는 어떻게 작동할까?
예제를 통해 알아보자
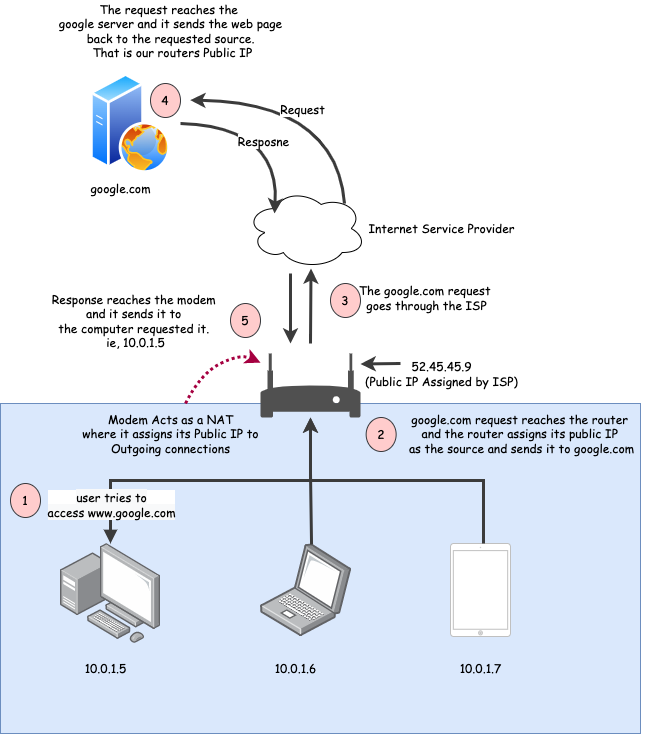
다음은 NAT 장치(라우터)를 통해 전달되는 요청의 상위 수준 아키텍처임
1단계 사설 네트워크에 있는 컴퓨터가 공용 웹사이트에 액세스를 시도함. 이 예에서는 google.com으로 가정
2단계 요청 패킷이 먼저 라우터에 도달함. 라우터에는 public IP 주소가 있음. 아래 이미지와 같이 public address를 요청 IP 패킷 헤더에 소스 IP 주소로 추가하고 요청을 전달함. (이 과정을 "masquerading"이라 부르기도 함)
3단계 요청이 서버(google.com)에 도달하고 소스를 서버 IP로 변경하고 대상을 라우터 공용 IP로 변경하여 웹페이지를 응답으로 보냄
4단계
응답이 라우터에 도달하면 대상 주소를 요청된 컴퓨터의 사설 IP 주소로 수정
라우터는 **NAT 테이블(**NAT 지원 장치에서 관리하는 고유한 테이블)을 통해 요청을 추적함
라우터는 NAT 테이블 정보를 사용하여 요청이 시작된 장치와 응답을 다시 보내야 하는 장치를 알고 있음
NAT은 뭐가 좋지?
NAT는 IPV4 고갈과 관련된 문제를 해결
RFC1918 (사설 IP 범위)은 NAT로 인해 가능
RFC1918 서브넷의 범위는 다음과 같음.
10.0.0.0/8
172.16.0.0/16(172.16/12 접두사)
192.168.0.0/16
NAT FAQ
NAT는 MAC 주소를 매핑합니까?
아니오. NAT는 패킷을 처리하는 네트워크 계층(계층 3)에서 작동합니다. MAC 주소는 데이터 링크 계층에 속합니다.
공용 IP 및 인터넷 연결이 있는 서버에 NAT가 필요합니까?
아니오. NAT는 사설 IP 범위가 있는 장치가 인터넷에 연결할 수 있도록 설계되었습니다.
포트 번호를 마스킹하는 이유는 무엇입니까?
네트워크에서 두 호스트 A와 B가 연결되어 있다고 가정합니다. 이제 둘 다 호스트 측에서 동일한 포트 번호(예: 1000)에서 동일한 대상을 동시에 요청합니다. NAT가 IP 주소만 변환하는 경우 패킷이 NAT에 도착하면 두 IP 주소가 모두 네트워크의 공용 IP 주소로 마스킹되어 대상으로 전송됩니다. 대상은 라우터의 공용 IP 주소로 응답을 보냅니다. 따라서 응답을 수신하면 어떤 응답이 어느 호스트에 속하는지 NAT에 명확하지 않습니다(A와 B의 소스 포트 번호가 동일하기 때문). 따라서 이러한 문제를 피하기 위해 NAT는 소스 포트 번호도 마스킹하고 NAT 테이블에 항목을 만듭니다.
NAT Types(3종류)
Static NAT
로컬주소가 공용 주소로 변환될 때, NAT은 같은 것을 선택함.
이것은, NAT 장치나 라우터에 연관된 일관성있는 공용 IP가 있다는 것을 뜻함.
Dynamic NAT
매번 같은 IP 주소를 선택하는 것 대신에, 이 NAT은 공용 주소 풀을 지남.
이것은 라우터가 로컬 주소를 공용 주소로 변환할 때마다 라우터나 NAT 장치가 다른 주소를 얻는 결과를 낳음.
PAT
PAT은 port 주소 변환을 위해 있음.
dynamic NAT의 종류이지만, 몇 가지 로컬 IP 주소들을 하나의 공용 주소로 묶음
모든 직원들의 활동이 하나의 IP를 사용하길 원하는 조직들은 때때로 네트워크 관리의 감시 아래 PAT을 사용함
IPv4 vs. IPv6
오늘날 시스템에 널리 구현되는 IP 프로토콜에는 IPv4와 IPv6의 두 가지 버전이 있음
Pv6은 프로토콜의 개선과 IPv4 주소 공간의 제한으로 인해 천천히 IPv4를 대체하고 있음 ⇒ 간단히 말해서, 현재 세계에는 IPv4를 통해 사용할 수 있는 주소의 양에 비해 너무 많은 인터넷 연결 장치가 있음
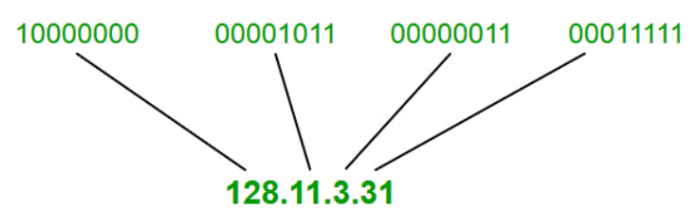
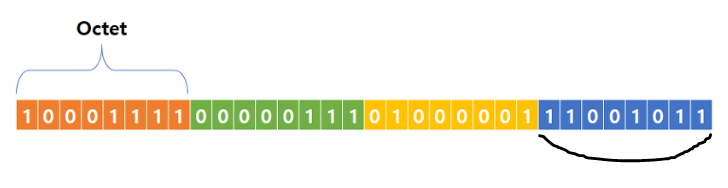
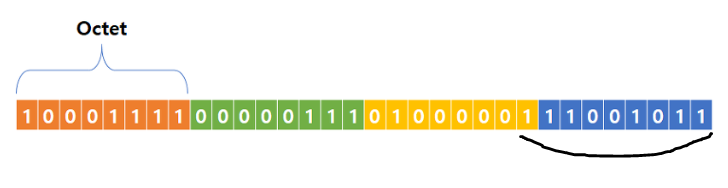
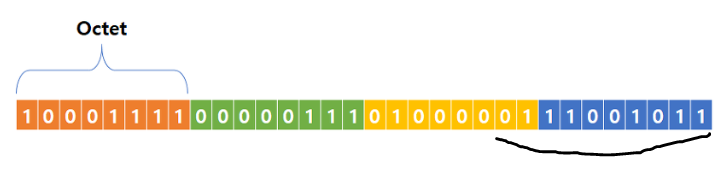
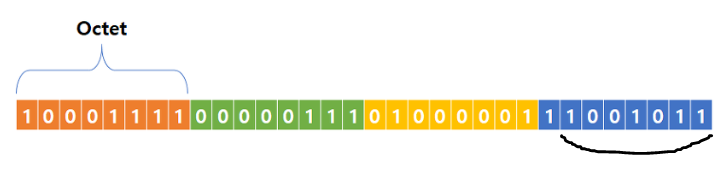
IPv4 주소는 32비트 주소입니다. 주소의 각 바이트 또는 8비트 세그먼트는 마침표로 나뉘며 일반적으로 숫자 0-255로 표시됨
이러한 숫자는 일반적으로 인간의 이해를 돕기 위해 10진수로 표시되지만, 각 세그먼트는 일반적으로 8비트의 표현이라는 사실을 표현하기 위해 옥텟 (octet)이라고 함
IPv4 형태?
일반적인 IPv4 주소는 다음과 같음
192.168.0.5
각 옥텟에서 가장 낮은 값은 0이고 가장 높은 값은 255임
이것을 이진법으로 표현하여 4개의 옥텟이 어떻게 보일지 더 잘 알 수 있음. 가독성을 위해 각 4비트를 공백으로 구분하고 점을 대시로 대체함.
1100 0000 - 1010 1000 - 0000 0000 - 0000 0101
⇒ 이 두 형식이 동일한 숫자를 나타낸다는 것을 인식하는 것은 나중에 개념을 이해하는 데 중요
IPv6 형태?
IPv4 및 IPv6의 프로토콜 및 백그라운드 기능에는 몇 가지 다른 차이점이 있지만 가장 눈에 띄는 차이점은 주소 공간임.
IPv6은 주소를 128비트 숫자로 표현함.⇒ 이 확장된 주소 범위를 표현하기 위해 IPv6은 일반적으로 4자리 16진수의 8개 세그먼트로 작성됨
16진수는 숫자 0-9를 사용하여 숫자 0-15를 나타내고 더 높은 값을 나타내는 숫자 a-f를 사용함
⇒ 이를 고려하면 IPv6에는 IPv4 주소 양의 28 배에 해당하는 7.9×10 이상의 공간이 있음.
일반적인 IPv6 주소는 다음과 같음
1203:8fe0:fe80:b897:8990:8a7c:99bf:323d
압축 형식으로 작성된 이러한 주소를 볼 수도 있음
IPv6 규칙을 사용하면 각 옥텟에서 선행 0을 제거하고 0으로 채워진 단일 그룹 범위를 이중 콜론(::)으로 바꿀 수 있음
IPv4의 특징
비연결 프로토콜
다양한 장치에 간단한 가상 통신 계층 생성 허용
메모리가 덜 필요하고 주소를 기억하기 쉬움
수백만 개의 장치에서 이미 지원되는 프로토콜
비디오 라이브러리 및 회의 제공
IPv6의 특징
계층적 주소 지정 및 라우팅 인프라
상태 저장 및 상태 비저장 구성
서비스 품질(QoS) 지원
인접 노드 상호 작용을 위한 이상적인 프로토콜
IPv4와 IPv6의 주요 차이점
IPv4는 32비트 IP 주소이고 IPv6은 128비트 IP 주소
IPv4는 숫자 주소 지정 방법인 반면 IPv6은 영숫자 주소 지정 방법
IPv4 바이너리 비트는 점(.)으로 구분되는 반면 IPv6 바이너리 비트는 콜론(:)으로 구분
IPv4는 12개의 헤더 필드를 제공하는 반면 IPv6은 8개의 헤더 필드를 제공
IPv4는 브로드캐스트를 지원하지만 IPv6은 브로드캐스트를 지원하지 않음
IPv4에는 체크섬 필드가 있지만 IPv6에는 체크섬 필드가 없음
IPv4와 IPv6을 비교할 때 IPv4는 VLSM(Variable Length Subnet Mask)을 지원하지만 IPv6은 VLSM을 지원하지 않음
IPv4는 ARP(Address Resolution Protocol)를 사용하여 MAC 주소에 매핑하는 반면 IPv6은 NDP(Neighbour Discovery Protocol)를 사용하여 MAC 주소에 매핑
IPv4 주소와 IPv6 주소의 차이점 요약
차이점의 근거
IPv4
IPv6
IP 주소의 크기
IPv4는 32비트 IP 주소입니다.
IPv6은 128비트 IP 주소입니다.
주소 지정 방법
IPv4는 숫자 주소이며 이진 비트는 점(.)
IPv6은 이진 비트가 콜론(:)으로 구분되는 영숫자 주소입니다. 16진수도 포함합니다.
헤더 필드 수
12
8
헤더 파일의 길이
20
40
체크섬
체크섬 필드가 있음
체크섬 필드가 없습니다.
예시
12.244.233.165
2001:0db8:0000:0000:0000:ff00:0042:7879
주소 유형
유니캐스트, 브로드캐스트 및 멀티캐스트.
유니캐스트, 멀티캐스트 및 애니캐스트.
Class 수
IPv4는 5가지 클래스의 IP 주소를 제공 합니다. 클래스 A에서 E.
lPv6은 무제한의 IP 주소를 저장할 수 있습니다.
구성
새로 설치된 시스템이 다른 시스템과 통신하려면 먼저 구성해야 합니다.
IPv6에서 구성은 필요한 기능에 따라 선택 사항입니다.
VLSM 지원
IPv4는 VLSM(가변 길이 서브넷 마스크)을 지원합니다.
IPv6은 VLSM을 지원하지 않습니다.
분열
단편화는 경로를 보내고 전달하여 수행됩니다.
조각화는 발신자가 수행합니다.
라우팅 정보 프로토콜(RIP)
RIP는 routed 데몬에서 지원하는 라우팅 프로토콜입니다.
RIP는 IPv6을 지원하지 않습니다. 정적 경로를 사용합니다.
네트워크 구성
네트워크는 수동으로 구성하거나 DHCP를 사용하여 구성해야 합니다. IPv4에는 더 많은 유지 관리 노력이 필요한 인터넷 성장을 처리하기 위한 여러 오버레이가 있습니다.
IPv6은 자동 구성 기능을 지원합니다.
최고의 기능
단일 NAT 주소를 허용하는 NAT(네트워크 주소 변환) 장치를 광범위하게 사용하면라우팅할 수 없는 수천 개의 주소를 마스킹하여 종단 간무결성을 달성할 수 있습니다.
방대한 주소 공간 으로 인해 직접 주소 지정이 가능 합니다.
주소 마스크
호스트 부분에서 지정된 네트워크에 사용합니다.
사용되지 않습니다.
SNMP
SNMP는 시스템 관리에 사용되는 프로토콜입니다.
SNMP는 IPv6을 지원하지 않습니다.
이동성 및 상호 운용성
이동이 제한되는 상대적으로 제한된 네트워크 토폴로지는 이동성과 상호 운용성 기능을 제한합니다.
IPv6은네트워크 장치에 내장된 상호 운용성 및 이동성 기능을 제공합니다.
보안
보안은 애플리케이션에 따라 다릅니다. IPv4는 보안을 염두에 두고 설계되지 않았습니다.
IPSec(Internet Protocol Security)은 IPv6 프로토콜에 내장되어적절한 키 인프라와 함께 사용할 수 있습니다.
패킷 크기
패킷 크기 576바이트 필요, 조각화 선택 사항
조각화 없이 1208바이트 필요
패킷 단편화
라우터 및 전송 호스트에서 허용
호스트만 보내기
패킷 헤더
체크섬 옵션을 포함하는 QoS 처리를 위한 패킷 흐름을 식별하지 않습니다.
패킷 헤드에는 QoS 처리를 위한 패킷 흐름을 지정하는 흐름 레이블 필드가 포함됩니다.
DNS 레코드
주소(A) 레코드, 호스트 이름 매핑
주소(AAAA) 레코드, 호스트 이름 매핑
주소 구성
수동 또는 DHCP를 통해
ICMPv6(Internet Control Message Protocol 버전 6) 또는 DHCPv6을 사용한 상태 비저장 주소 자동 구성
IP 대 MAC 해상도
브로드캐스트 ARP
멀티캐스트 이웃 요청
로컬 서브넷 그룹 관리
인터넷 그룹 관리 프로토콜 GMP)
멀티캐스트 수신기 검색(MLD)
선택 필드
선택적 필드가 있음
선택적 필드가 없습니다. 그러나 확장 헤더를 사용할 수 있습니다.
IPSec
네트워크 보안과 관련된 IPSec(인터넷 프로토콜 보안)은 선택 사항입니다.
IPSec(Internet Protocol Security) 네트워크 보안 관련 필수
동적 호스트 구성 서버
클라이언트는 네트워크에 연결하려고 할 때마다 DHCS(동적 호스트 구성 서버)에 접근합니다.
클라이언트는 영구 주소가 제공되므로 이러한 서버에 접근할 필요가 없습니다.
매핑
ARP(Address Resolution Protocol)를 사용하여 MAC 주소에 매핑
NDP(Neighbour Discovery Protocol)를 사용하여 MAC 주소에 매핑
모바일 장치와의 호환성
IPv4 주소는 점-10진수 표기법을 사용합니다. 그렇기 때문에 모바일 네트워크에는 적합하지 않습니다.
IPv6 주소는 콜론으로 구분된 16진수로 표시됩니다. IPv6은 모바일 네트워크에 더 적합합니다 .
듀얼 IP?
IPv4와 IPv6은 서로 통신할 수 없지만 동일한 네트워크에 함께 존재할 수 있고 이것을 듀얼 스택이라 함
Dual-IP 스택을 사용하면 컴퓨터, 라우터, 스위치 및 기타 장치가 두 프로토콜을 모두 실행하지만 IPv6이 기본 프로토콜임
IPv6는 어떤 점이 좋을까?
더 이상 NAT(네트워크 주소 변환)는 필요하지 않음
자동 구성
더 이상 개인 주소 충돌이 없음
더 나은 멀티캐스트 라우팅
더 간단한 헤더 형식
간소화되고 더 효율적인 라우팅
"흐름 레이블 지정"이라고도 하는 진정한 서비스 품질(QoS)
내장된 인증 및 개인 정보 보호 지원
유연한 옵션 및 확장
더 쉬운 관리(더 이상 DHCP 필요 없음)
더 많은 주소를 지원
IPv4는 인터넷 주소로 32비트 주소를 사용.⇒ 많은 것처럼 보일 수 있지만 현재 42억 9천만 개의 IP 주소가 모두 할당되어 오늘날 우리가 직면한 주소 부족 문제로 이어짐⇒ IPv6 주소의 수는 IPv4 주소의 수보다 1028배 더 많기 때문에, 인터넷 장치가 매우 오랫동안 확장될 수 있도록 충분한 IPv6 주소가 있음.
⇒ IPv6은 128비트 인터넷 주소를 사용하기 때문에, 2^128개의 인터넷 주소(정확히 340,282,366,920,938,463,463,374,607,431,768,211,456)를 지원 가능
⇒ 즉, 총 2^32개의 IP 주소(약 42억 9천만 개)를 지원
부탁드리는 사항
혹시 잘못된 내용이나, 인용/차용 등에 있어 문제의 소지가 되는 내용이 있다면 언제든 알려주시면 큰 도움이 될 것 같습니다!
삼각형의 세 변의 길이 A, B, C 중에서 한 변의 길이를 뽑았을 때, 나머지 두 변의 길이의 합 보다 작아야 한다.(세 변의 길이 모두 부합하여야 함)
⇒ 이 규칙을 좀 더 간단히 해보면?
⇒ “가장 큰 변의 길이 < 나머지 변의 길이의 합”이 부합한다면, 나머지 2조건은 자동적으로 성립할 것
2. 가장 간단하게 푸는 방법?
정수 배열로 가능한 모든 순열 조합을 뽑아 낸 후에 삼각형 만들 수 있는 조건 검토
⇒ O(3N^3)으로 불가능
3. 시간복잡도는 얼마나 수용 가능한가?
⇒ O(10N^2) 정도까지 수용 가능할 것
4. 좀 더 단순화 해본다면?
제약조건을 걸어서 선택지를 좁혀보자
⇒ 가장 큰 숫자를 고정시키고 해당 숫자를 바탕으로 가능한 나머지 숫자 2개의 조합을 찾기
⇒ for largest_idx in range(len(nums)) : O(N)
⇒ 나머지 숫자를 찾는 방식을 O(N)으로 끝내야 함
⇒ 한 배열을 1번만 돌면서 가능한 두 숫자의 조합을 찾아야 함
⇒ Two Pointers 알고리즘 활용
5. 풀이방식
데이터 전처리 : 배열 오름차순 정렬
배열 뒤에서부터 돌면서 가장 큰 값 고정시켜줌
가장 큰 값이 고정된 상태에서 나머지 두 값 찾기
right값을 기준으로 가능한 최소 left값을 찾아서 그 사이의 값들은 해당 right값과 무조건 조건에 부합한다는 방식으로 찾기
어려웠던 점
right값과 left값을 찾음에 있어서도 한 값을 기준으로 생각해야하는데, 처음에 두 개 모두 기준으로 생각해서 혼란이 왔다.
중간에 더 시간복잡도를 줄이기 위해, 어느 하나의 largest_idx에서 가능한 조합이 0개가 나오면 더 이상 확인할 것도 없다는 생각에 곧바로 answer를 return해줬는데, [3, 19, 22, 24, 35, 82, 84] 와 같은 경우도 있을 수 있기 때문에 해당조건은 걸어두면 안 되었다.
느낀점
항상 느끼는 거지만, 코딩테스트 문제는 부지런히 풀어야 익숙해지는 것 같다.
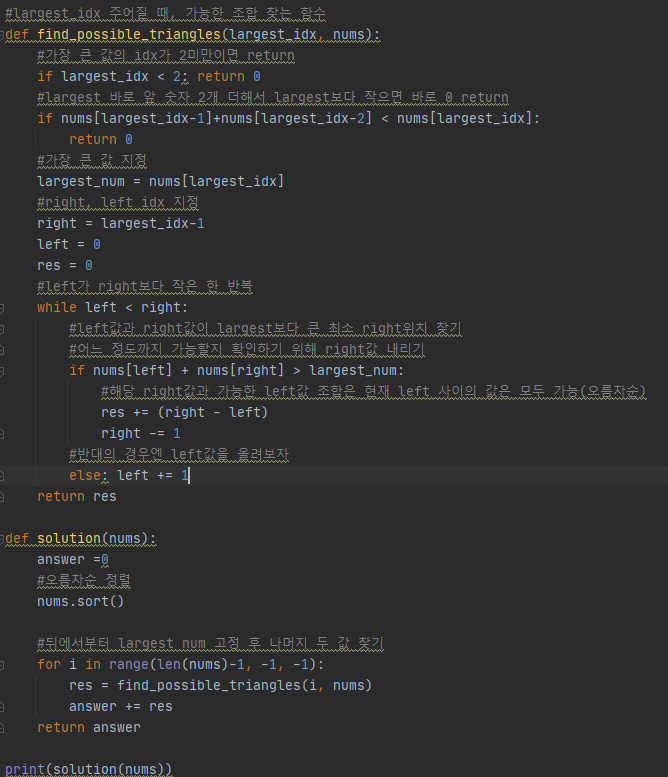
내 코드
#largest_idx 주어질 때, 가능한 조합 찾는 함수
def find_possible_triangles(largest_idx, nums):
#가장 큰 값의 idx가 2미만이면 return
if largest_idx < 2: return 0
#largest 바로 앞 숫자 2개 더해서 largest보다 작으면 바로 0 return
if nums[largest_idx-1]+nums[largest_idx-2] < nums[largest_idx]:
return 0
#가장 큰 값 지정
largest_num = nums[largest_idx]
#right, left idx 지정
right = largest_idx-1
left = 0
res = 0
#left가 right보다 작은 한 반복
while left < right:
#left값과 right값이 largest보다 큰 최소 right위치 찾기
#어느 정도까지 가능할지 확인하기 위해 right값 내리기
if nums[left] + nums[right] > largest_num:
#해당 right값과 가능한 left값 조합은 현재 left 사이의 값은 모두 가능(오름차순)
res += (right - left)
right -= 1
#반대의 경우엔 left값을 올려보자
else: left += 1
return res
def solution(nums):
answer =0
#오름차순 정렬
nums.sort()
#뒤에서부터 largest num 고정 후 나머지 두 값 찾기
for i in range(len(nums)-1, -1, -1):
res = find_possible_triangles(i, nums)
answer += res
return answer
print(solution(nums))